I have a question about integrating FME with ArcGIS Online (which I will be using to create an Open Data site). I am exploring using FME as the method for pushing data updates to our feature services. I have tested this successfully with small datasets, but ran into issues (understandably) with our large parcel dataset (~400,000 parcels). This is very slow to run with the Update Detector method as well as a Truncate and re-populate method. Has anyone ran into this issue and do you have any suggestions for how to do this with larger datasets like this? Any tips or tricks I'm missing?
I am thinking that for large datasets we may have to manually publish from ArcMap or Pro (since it takes less than 5 mins), but it would be ideal for us to use an FME workspace for each dataset to keep it clean and consistend. However, if processing time is 2+ hours then that is definitely not the best solution.
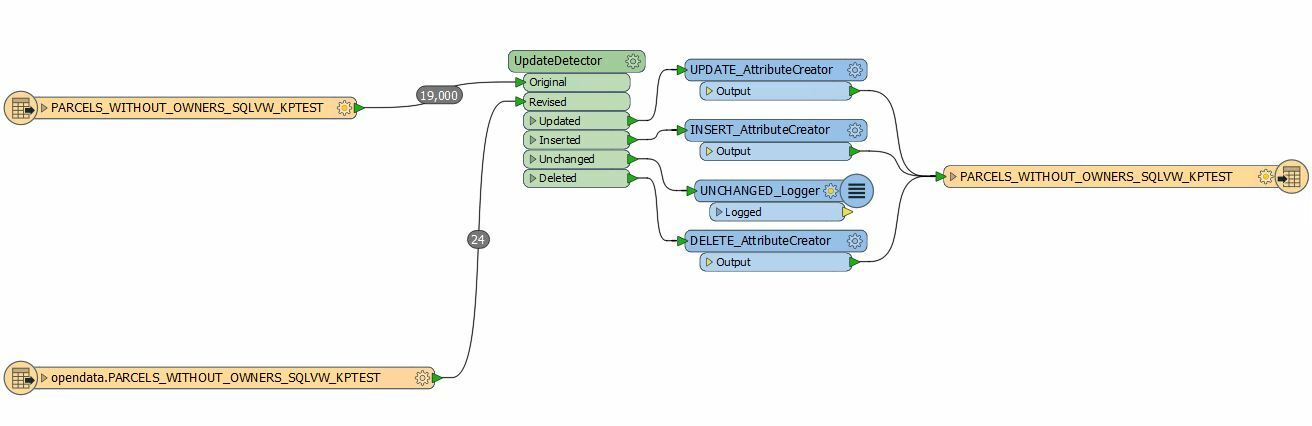
Here is a screenshot of my (currently running) workspace. I have limited the revised source to just look at updates from the past 7 days (supposing I would run this weekly). I am using fme_db_operation to pass the type of update to the writer.