Hi everyone,
I have struck a roadblock in the creation of a particular FME Workbench that I now require help with. I appreciate your time in advance.
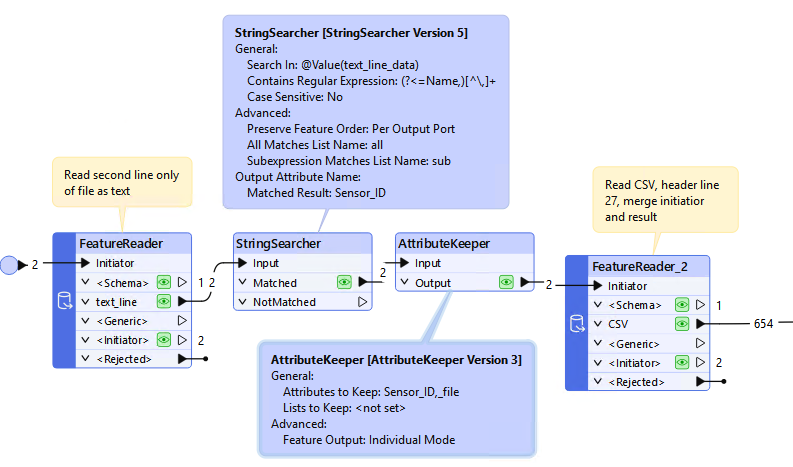
I have multiple csv files that contains a table of data that I would like to process into a single csv file table.
Lines 1-26 of these files contains general information
Line 27 contains headers for a table below
Line 28 onwards contains the data for the table.
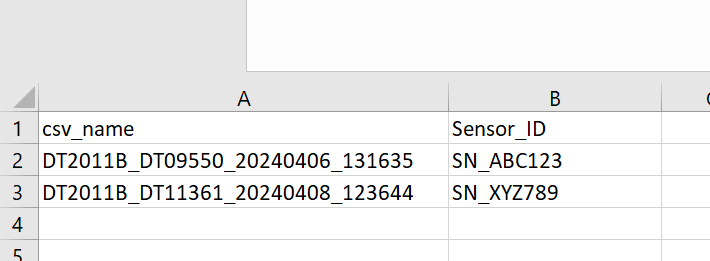
In Line 2 Row 2 there is a “cell” (B2) which contains text which I would like to add into a new column in the table repeatedly.
I have done and been able to do the following:
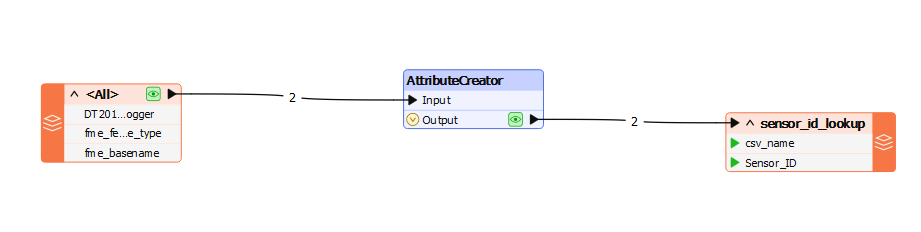
- Used 2 x CSV Readers
- 1st CSV Reader data is transformed down to just cell B1 and B2, with B1 text being replaced with a header name 'Sensor_ID' and B2 simply being the original data in B2 eg. SN_ABC123
- 2nd CSV Reader data is transformed to Line 27 onwards (i.e. just showing the table), plus a few other modifications using AttributeRenamer, AttributeRemover etc.
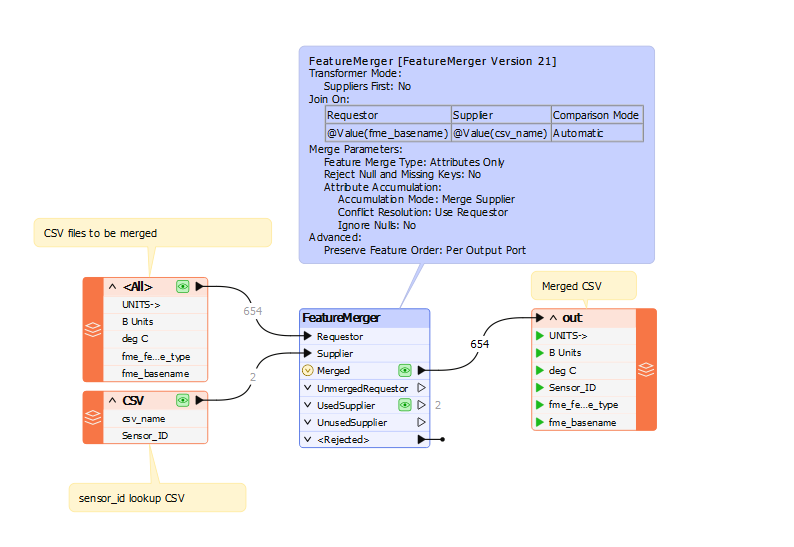
- Tried using both FeatureMerger and FeatureJoiner to merge the 1st CSV Reader data with the 2nd, such that 'Sensor_ID' becomes a new header for a new column with the data from B2 (eg. SN_ABC123) being populated the full extent of the column.
The problem I have is that when working with multiple CSV files (I sometimes process up to 40) the data from Sensor_ID does not match up correctly with the data in the table. i.e. the wrong Sensor_ID eg. SN_ABC123, with the wrong values in the table.
I am using FME Workbench 2024.1. I have tried joining with FeatureMerger and FeatureJoiner. I have tried joining via a name like FME_basename and FME_Dataset.
I have attached two modified csv files as examples of the raw data to be processed in FME. The output I want is something like in the 3rd file.
Any help would be greatly appreciated.
Thanks,
Luke