

Hi everybody,
I have written a very simple script that:
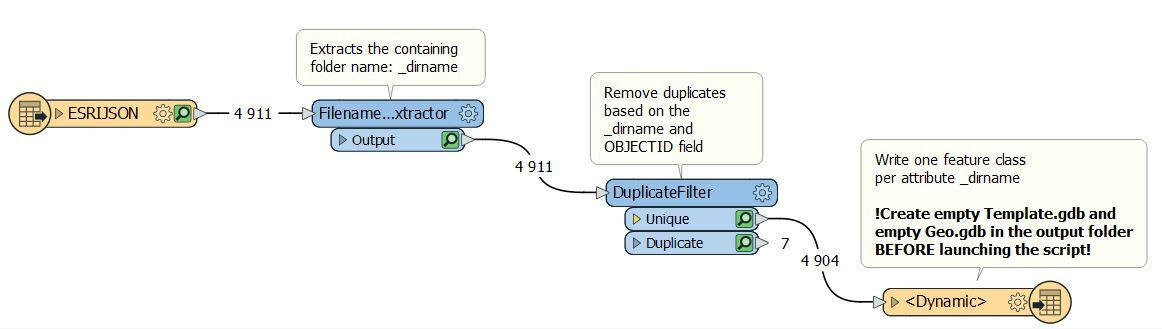
- Reads some ESRI-JSON placed in folder tree recursively (**/*.json)
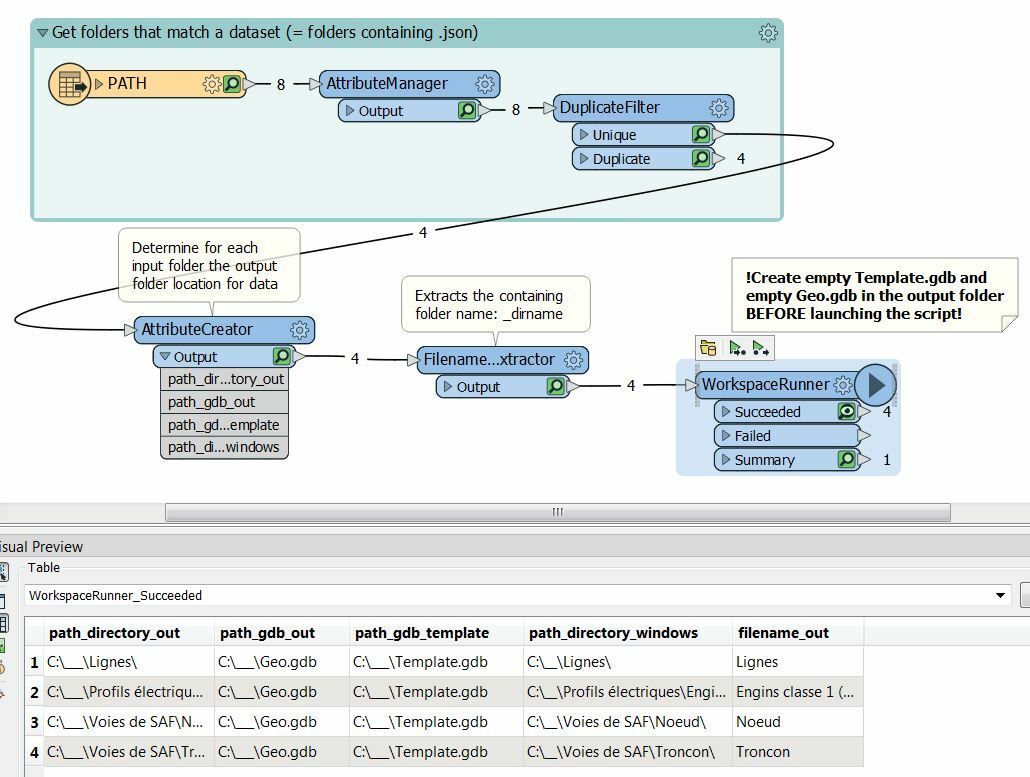
- For every data which is in the same folder (= same type of data), gathers all entries in the same dataset and creates a new feature class with the name of the folder in an ESRI file geodatabase (having eliminated duplicates)
Precisions:
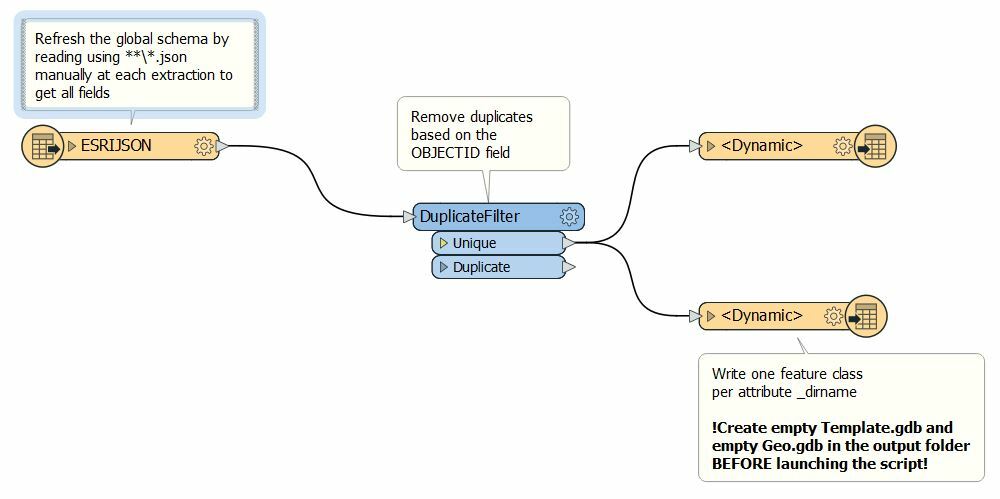
- Every input json files in the same folder share the same schema. But in differents folders the schemas are not the same and there may be or not M values attached to the data.
- However, the field OBJECTID can always be found and that key is used to remove duplicates.
Issue:
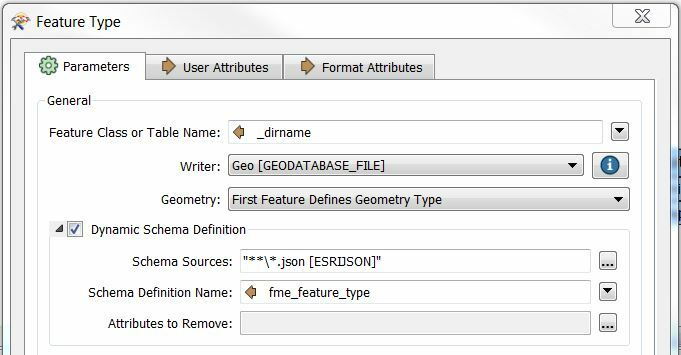
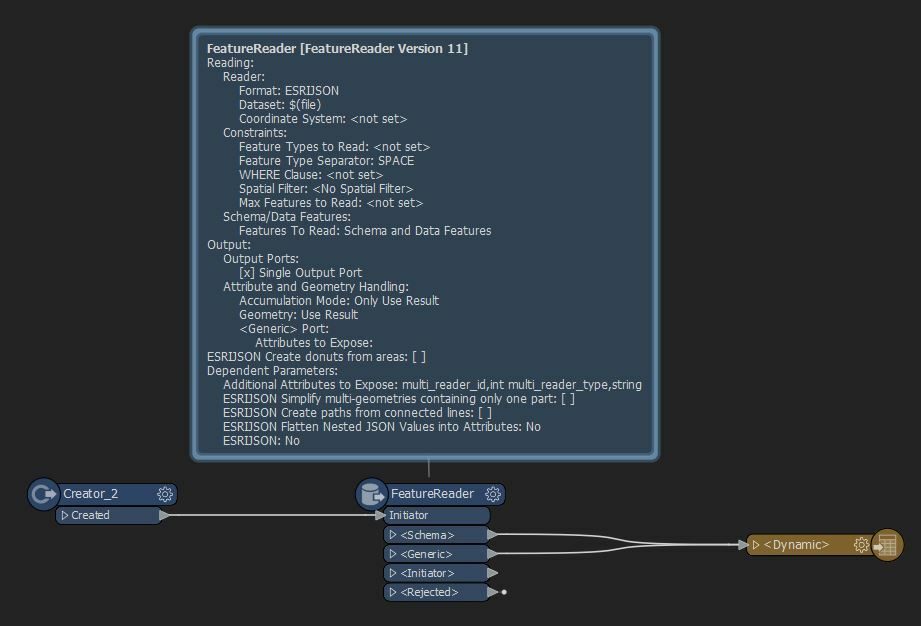
I cannot find the way of setting the output port to retrieve the original schema which is the same of the JSON files the output dataset aggregates. When I check "Dynamic Schema Definition" I have no choice but to use fme_feature_type (the script fails otherwise) attribute but it represents the whole schema (since all files are ESRI-JSON); so there are lots of useless fields in the result...
What would be the proper setting in your opinion?
Below you can find a snapshot of the script used as well as the current parameters used for output.
Thanks for your help!
 How are you specifying the name for your dataset?
How are you specifying the name for your dataset?


















