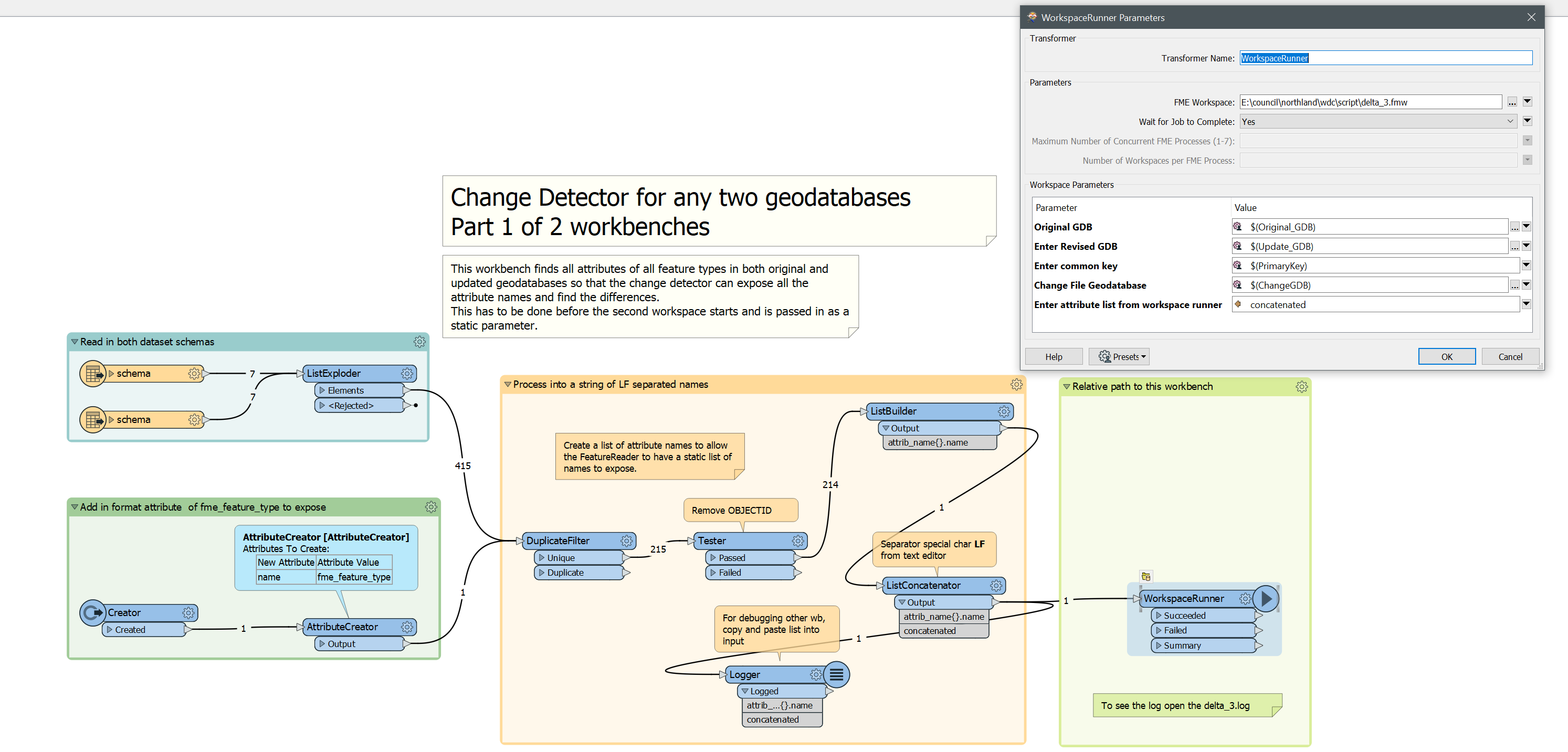
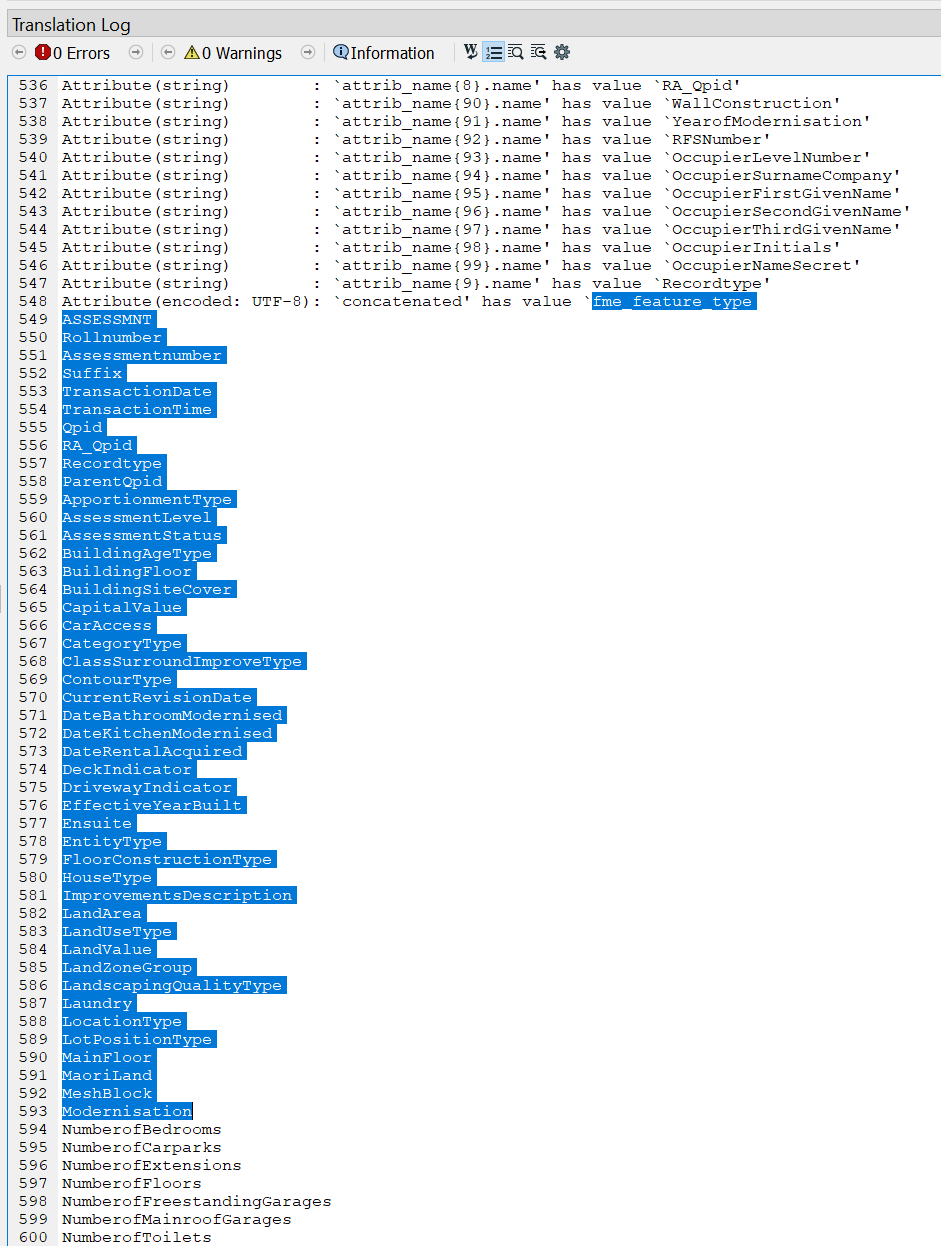
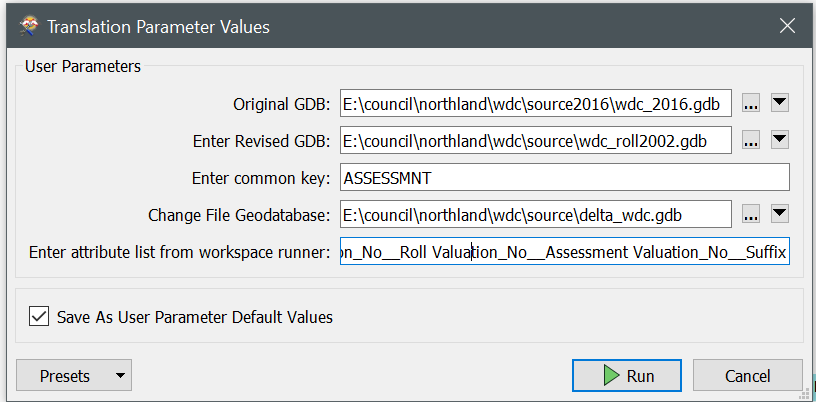
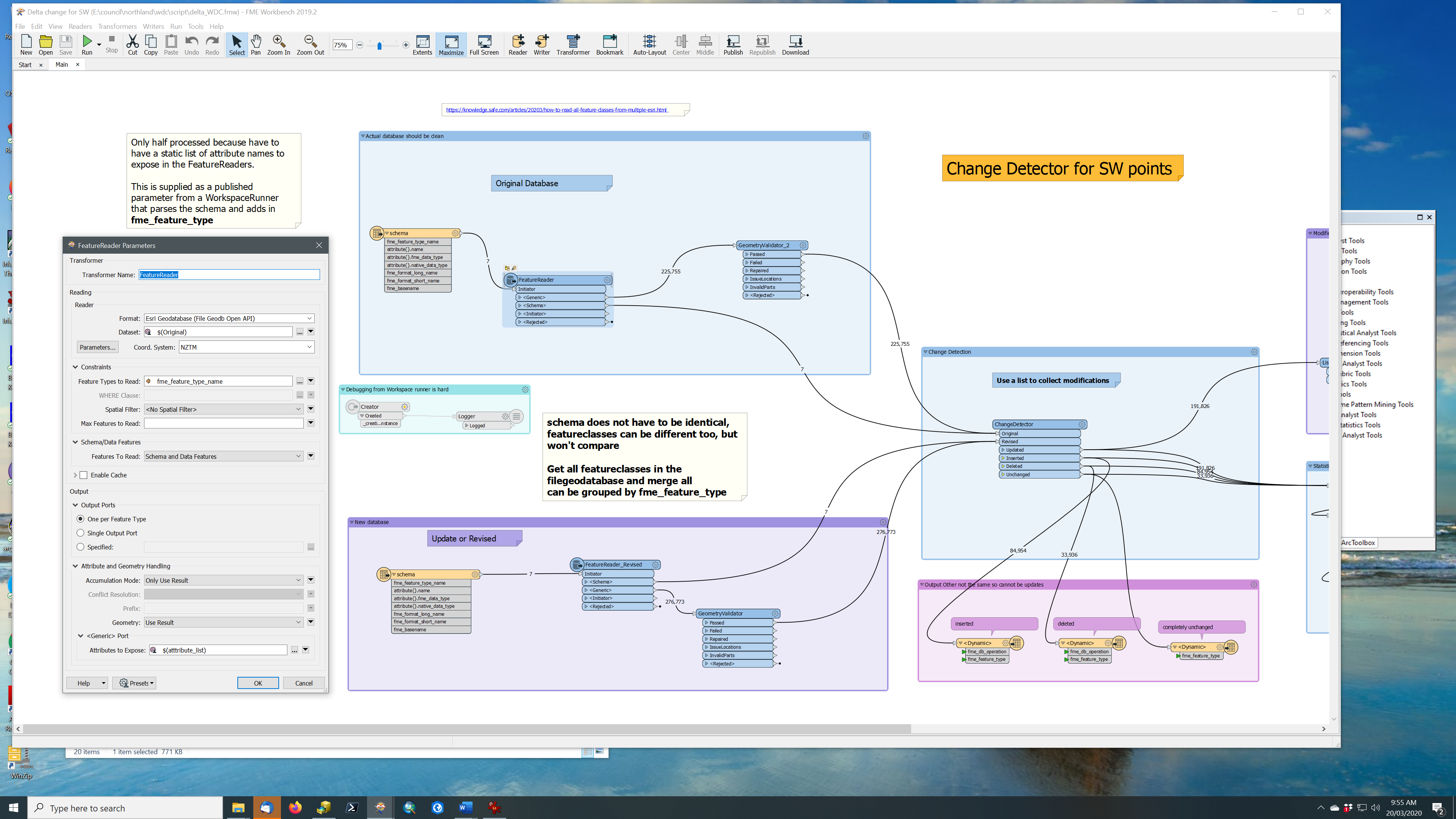
I am trying to construct my first custom transformer and have some issue with the schema handling.
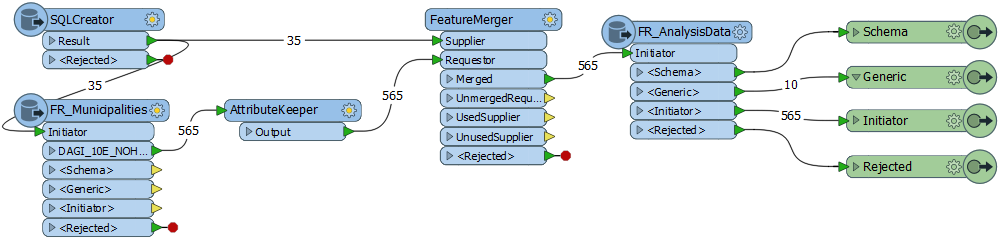
To explain what I am doing in my transformer:
The SQLCreator is pulling information from a PostgreSQL table. The information retrieved are used to extract polygons from a Oracle database in the subsequent FeatureReader (FR_Municipalities). here the requested feature type is static. Cleaning up some attributes and joining a timestamp from the initial PostgreSQL table, the polygons are used to extract data from another table in the Oracle database. The difference here is, that the user has to have the possibility to select the feature type in the last FeatureReader(FR_AnalysisData).
Since the feature type is based on a published parameter, there is no specific output port, but all goes trough the generic port. Here I have the problem that basically all attributes should be pulled, but how to say that in the dialogue where I specify the attributes to expose?
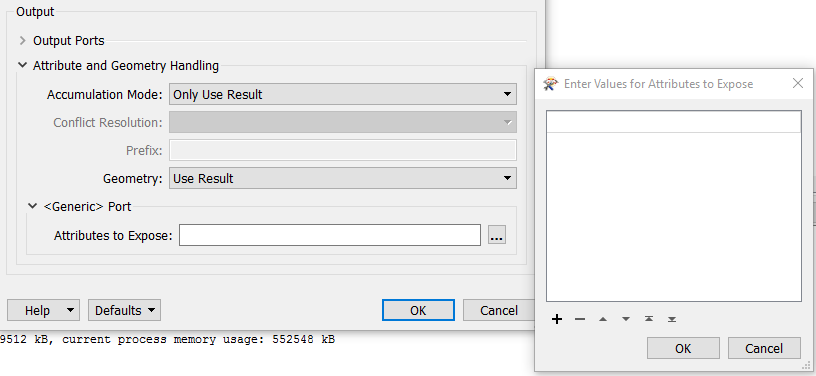
Is there some sort of wildcard to do so?






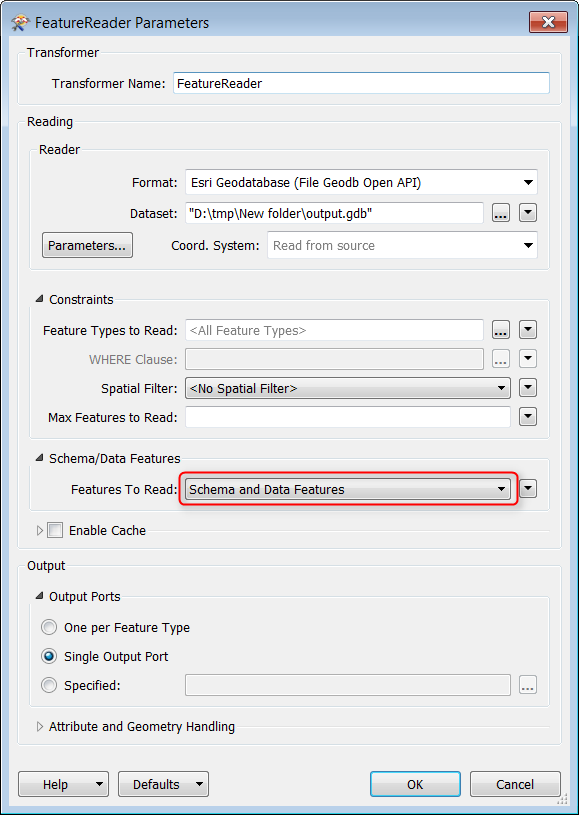










")