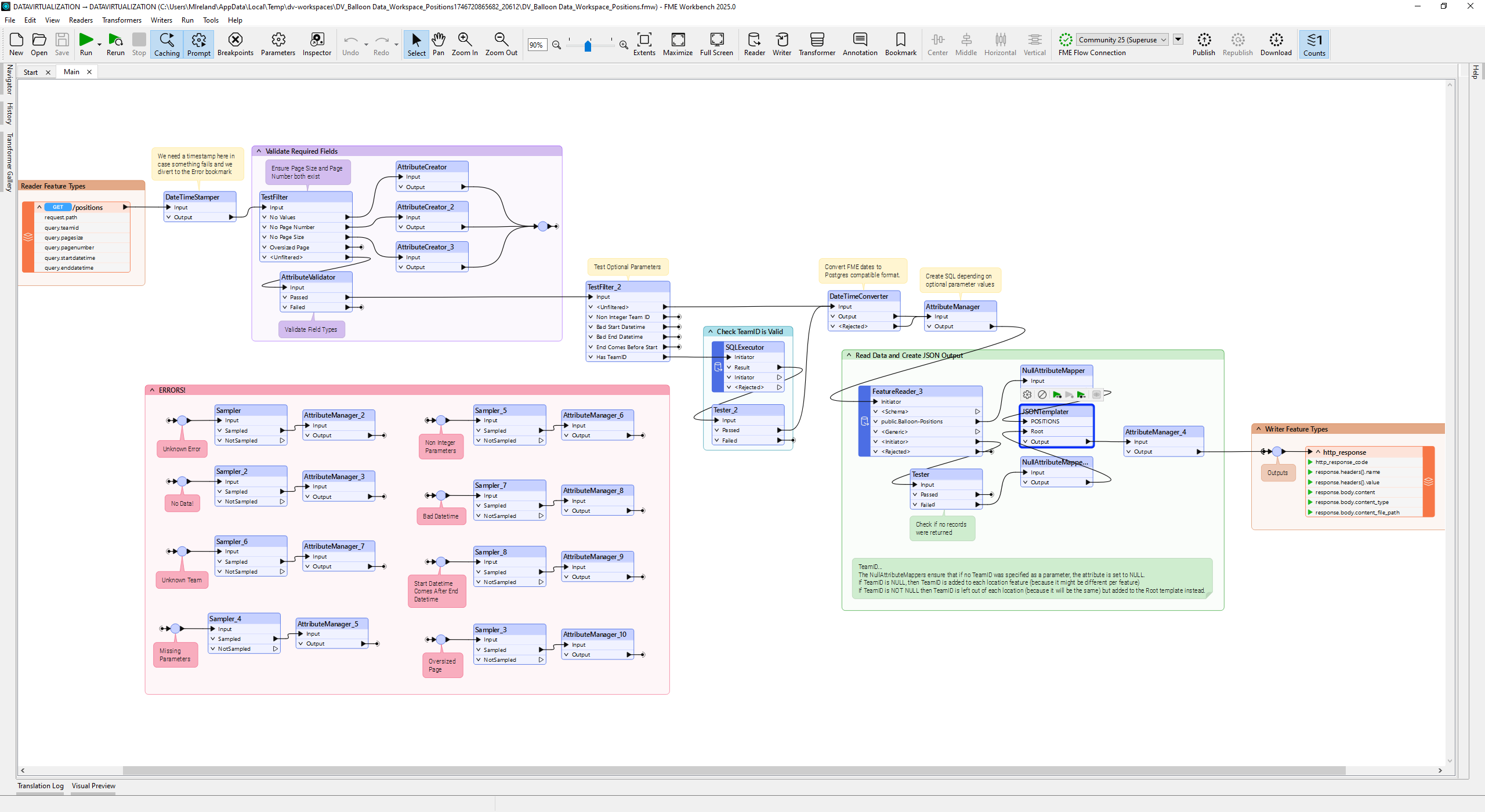
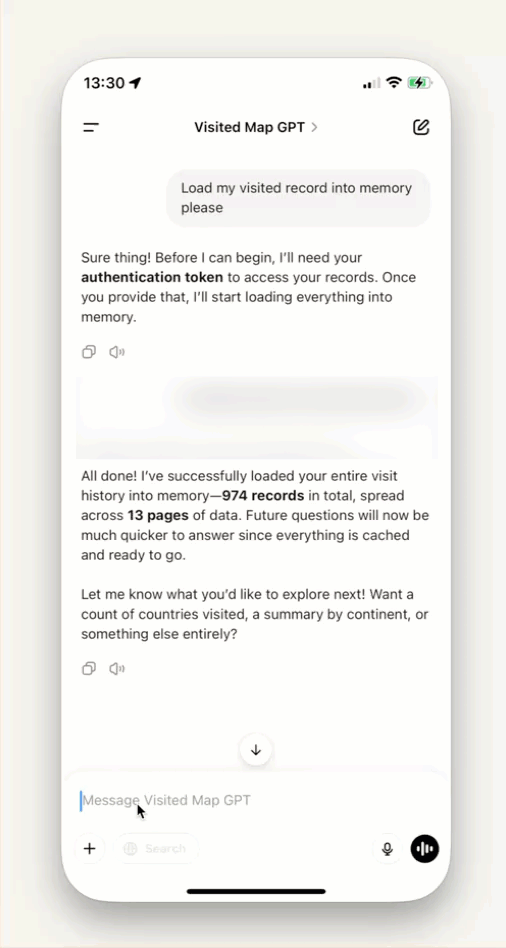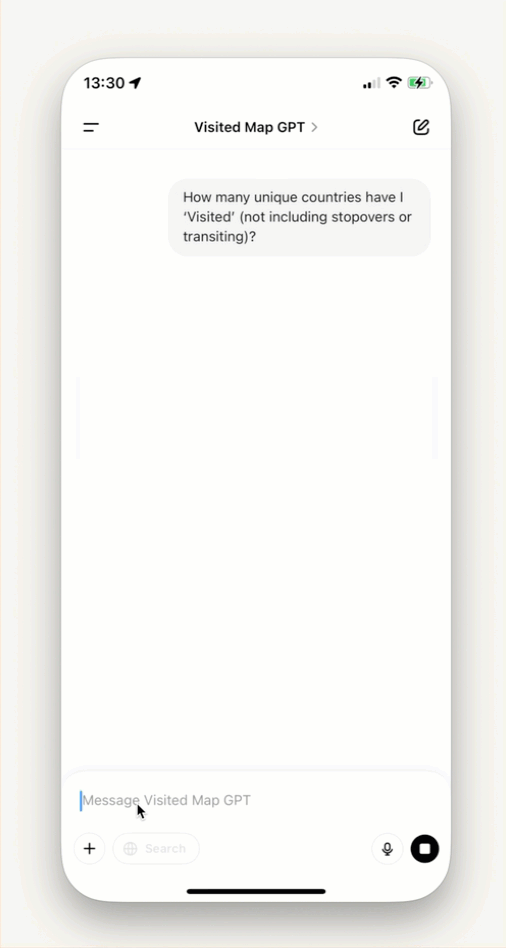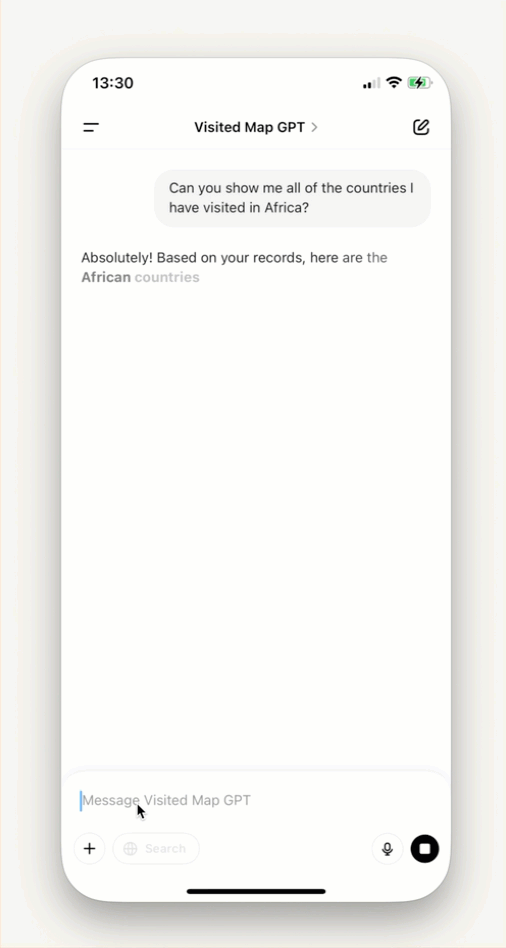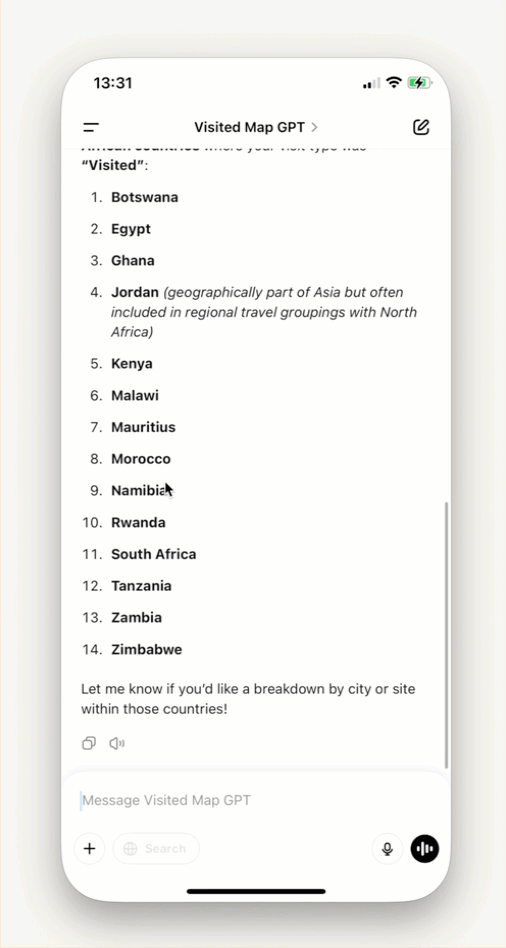
We are excited to announce a powerful new capability in FME: Data Virtualization – designed to bring the full power of FME directly into your applications, without having to build additional infrastructure or writing custom code.
With FME Data Virtualization, you can now build secure, AI-ready, OpenAPI-compliant REST APIs directly on top of any system or data source FME supports. Complete CRUD (Create, Read, Update, Delete) functionality with built-in caching, security, all through our no-code interface.
Why it matters
- Real-time access to any source: Expose APIs using FME workflows to engage systems without moving or duplicating data.
- AI-ready OpenAPI endpoints: Enable LLMs, agents, and AI platforms to interact with enterprise data securely.
- Built-in governance: Apply filters, authentication, and permissions to control exactly what gets shared.
- Streamlined innovation: Empower developers and data teams to create APIs without custom code or additional infrastructure.
Capabilities at a Glance
Filter to create custom views of data, eliminating sensitive or irrelevant information. Gain control and increase security by allowing only authenticated users and applications to access APIs.
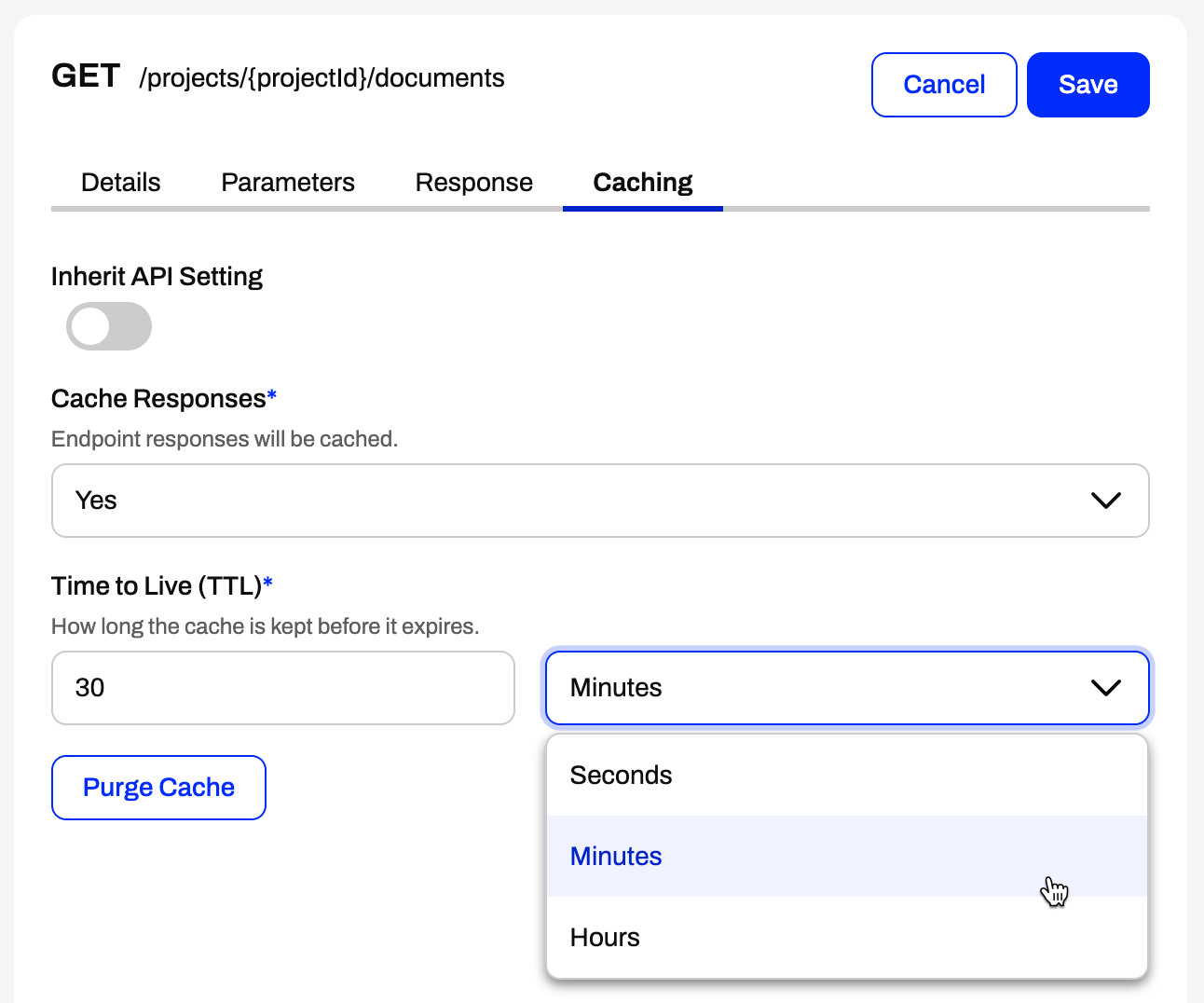
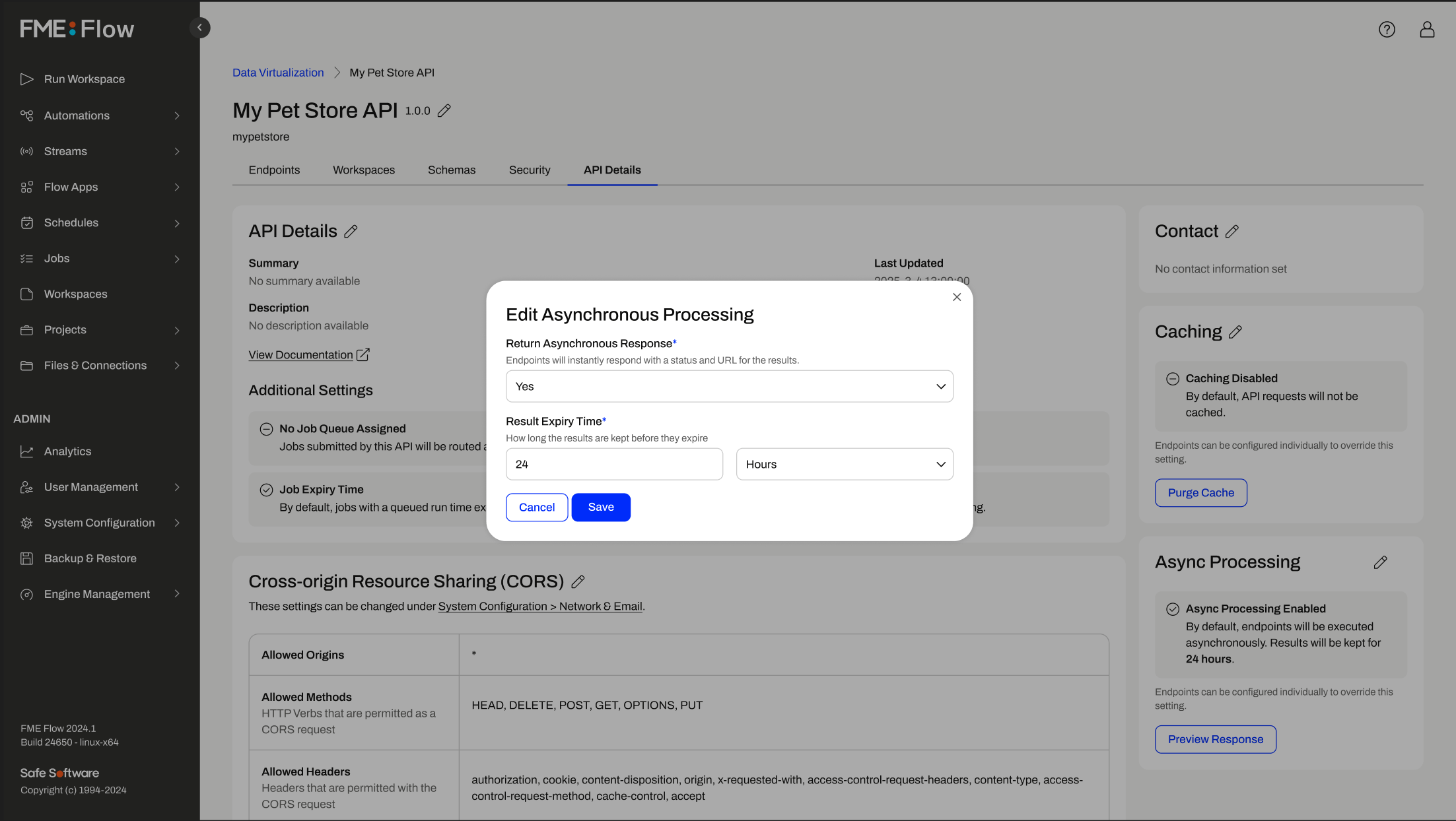
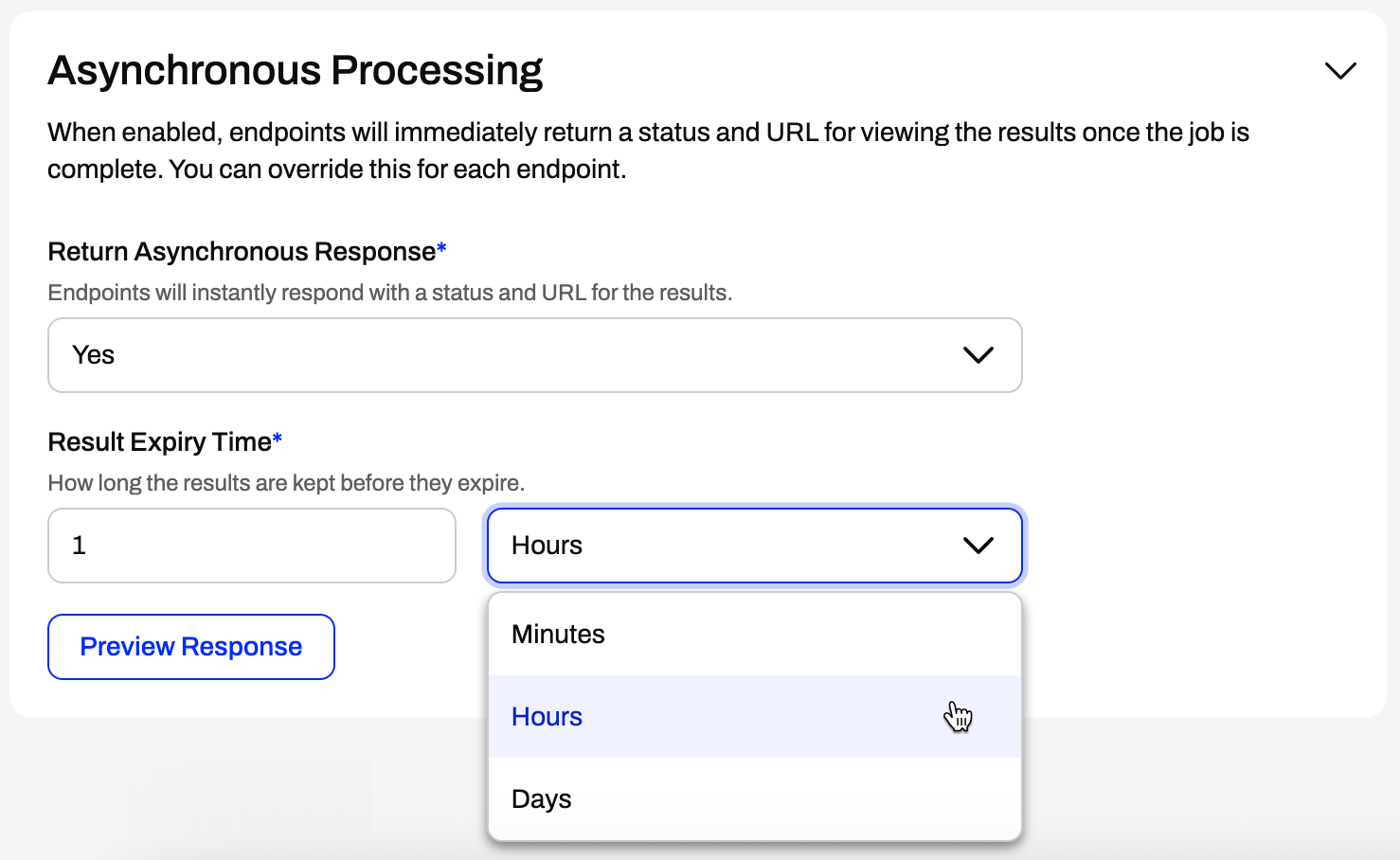
Caching for high speed endpoint requests - deliver faster response time, for common or static requests. Better performance and reduced system load.
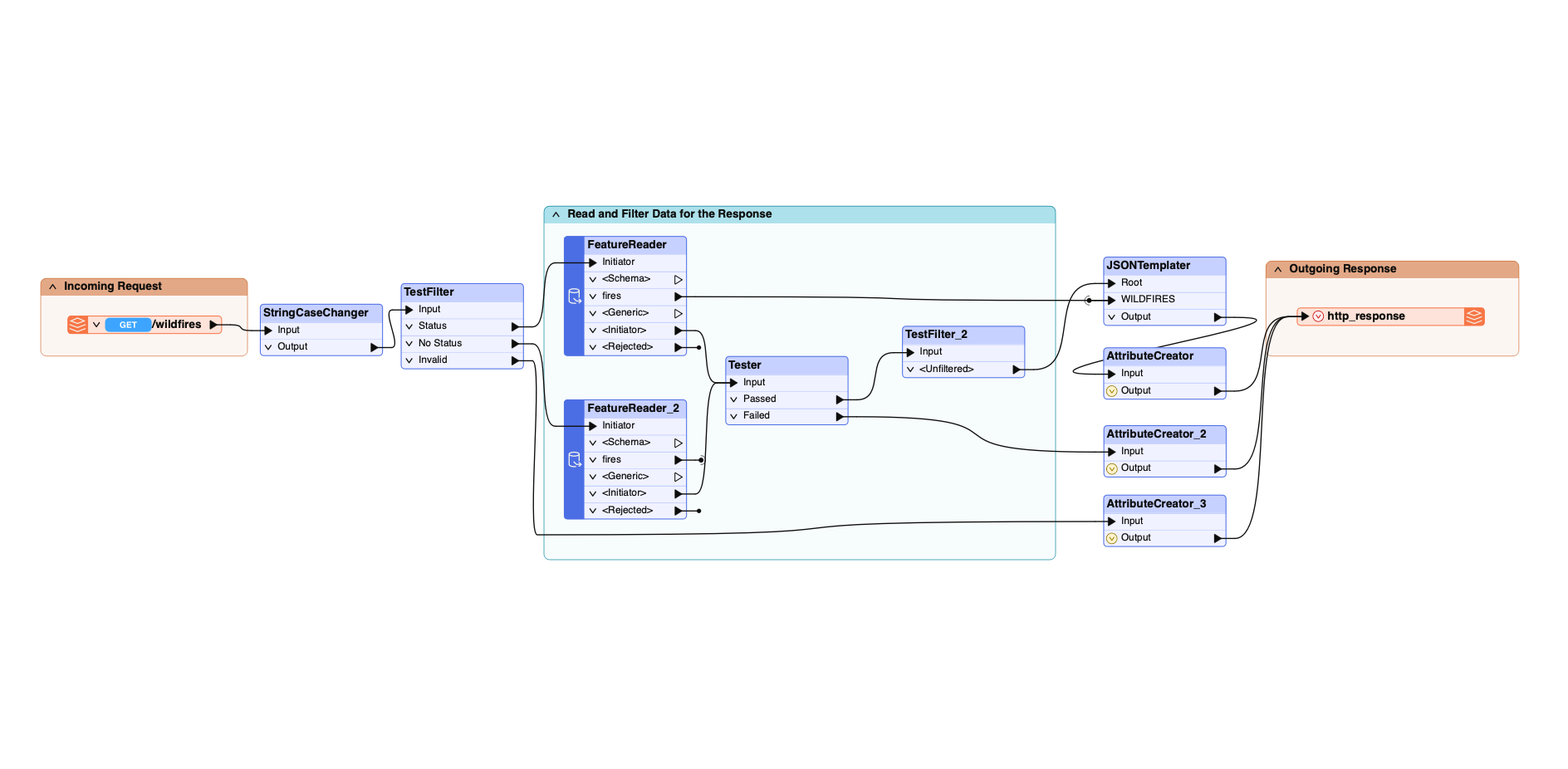
AI-Ready OpenAPI Endpoints – AI tools can readily ingest Data Virtualization endpoints so you can use natural language to interact with data.
Synchronous & Asynchronous endpoints - gives the application developer maximum flexibility to decide how they want to engage the application layer.
Download 2025.1 Data Virtualization beta here
Check out "Getting Started with Data Virtualization" knowledge based article here
Join our upcoming webinar “Data Virtualization: Bringing the Power of FME to Any Application” on June 4, 2025.
























")