Starting out with feature reader, and I am definitely missing something. The input dataset has about 1,600 records. Why is the output at 366,458 (and counting) about 10% of the way through?
Thank you,
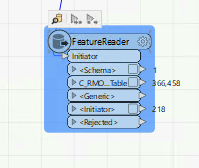


Starting out with feature reader, and I am definitely missing something. The input dataset has about 1,600 records. Why is the output at 366,458 (and counting) about 10% of the way through?
Thank you,
Best answer by geomancer
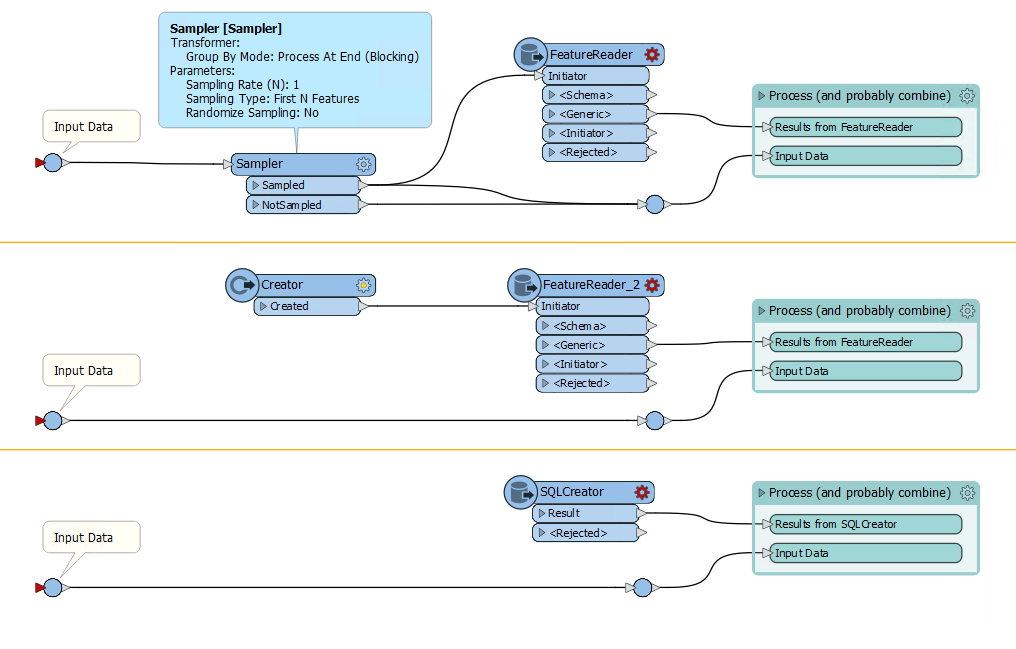
Visualization of the three different possibilities I mentioned.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.


