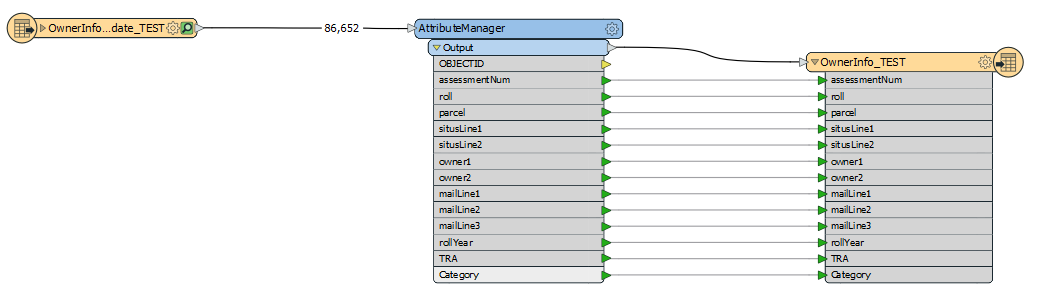
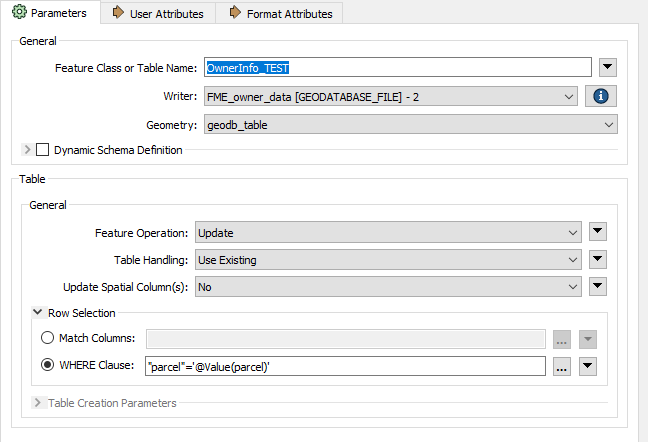
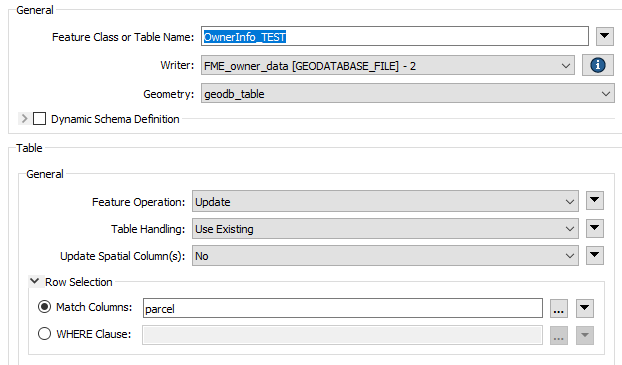
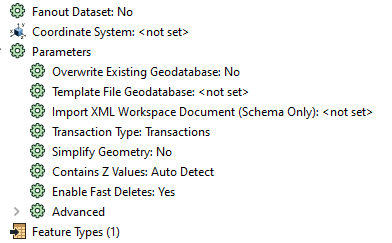
Using AttributeManager to update 86,000 (existing) records using APN for key. Is this process optimized by FME? It takes a long time, and I assume it is N*N time. (Does the Reader iterate through each record, one at a time, then searching through all the records in the Writer to find the matching key?)

Question
Using AttributeManager to update attributes in the Writer from matching records from the Reader. Takes a long time. 6 hours for 86,000 records. Is this normal?



Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.