


Hello FME'ers,
This question-of-the-week comes from GIS/StackExchange; the first one I've taken from there I believe.
Question of the WeekThe question was asked by Jochen in Germany, who wanted to know how to carry out an INSERT on selected records only.
Q) I have a PostGIS table of, lets say, addresses, for example
id | adr | geom
----------------------------
1 | Rathausplatz 1 | POINT
2 | Dorfstraße 2 | POINT
3 | Kirchenweg 3 | POINTWith FME I would like to insert features to my adresses table but only features that do not exists (based on non-equality of attribute adr), i.e. for incoming features
adr | geom
----------------------------
Rathausplatz 1 | POINT
Dorfstraße 2 | POINT
Schlossallee 42| POINT
Elisenstraße 8 | POINTonly Schlossallee 42 and Elisenstraße 8 should be INSERTed, the first two should be rejected.
How to achieve this?
A) It's sort of an inverse update required here. Instead of updating a record that exists, we're inserting a record that doesn't. Sadly there isn't a set method for that.
One way would be to set up the database with a unique ID constraint, pass every record as an INSERT, and let the database deal with the fallout of pre-existing IDs.
But in FME, to find if a record doesn't already exist, we must query the database. So what's the best way to do this?
The Accepted AnswerOne answer - that was accepted very quickly - suggested using a FeatureMerger:
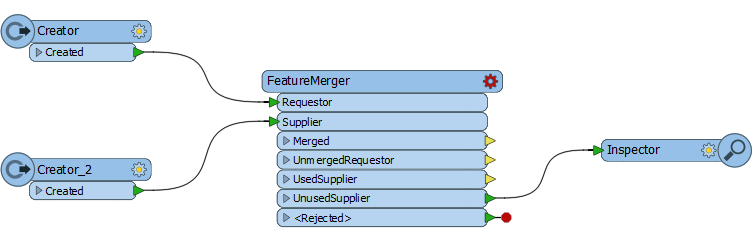
My instinct is that this is not a good answer. It won't work very quickly because the FeatureMerger is an older (and slower) transformer, plus why would you want to read all of your data into the workspace unnecessarily?
Having earlier this week updated our main Performance Tuning article on the Knowledgebase, I was in a good position to try out some of the suggested techniques.
I set up a scenario where I have a table on PostGIS (PostalAddress) and I have the same dataset in Geodatabase. I want to find which addresses in the Geodatabase already exist in PostGIS.
Then I tried a variety of solutions...
Read and Compare MethodsThe first two methods I tried involve - as in the accepted answer - reading all the data and doing a match
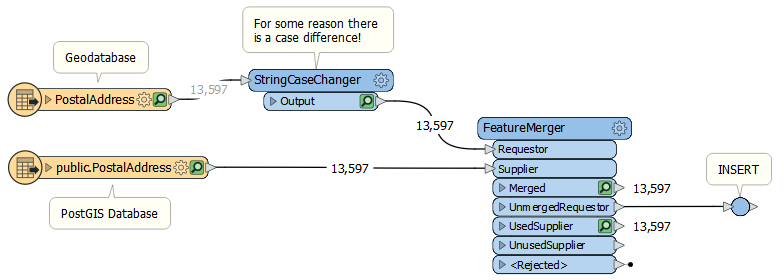
Obviously we keep the unmerged records and then do the INSERT. There aren't any unmerged records here because my two datasets are the same, but that's OK. I just wanted to evaluate the process.
Firstly I used the FeatureMerger, then I tried with the FeatureJoiner.
But are there any other methods?
SQL MethodsSince we're using a database, I next tried to use SQL to solve the requirement.
My instinct told me a SQLExecutor would actually be the best solution, to create a count of how many records match. So each Geodatabase record sends the query:
select count(*) as mycount from "public"."PostalAddress" where "PostalAddress"."PostalAddressId" = ''Then I would test for mycount >= 1 and drop those features.

Then we're absolutely not reading more data than necessary.
The other SQL method that occurred to me was to read data with a SQLCreator (rather than a reader)
select "PostalAddressId" from "public"."PostalAddress"Then I wouldn't need to read the spatial component, just the match keys. I would follow this up with a FeatureMerger/Joiner, as above, to do the actual comparison.
Direct Join MethodsFinally I tried two methods that compared records directly, without reading all of the PostGIS data.
The first of these is a FeatureReader with a WHERE clause
WHERE "PostalAddress"."PostalAddressId" = ''The second of these is a DatabaseJoiner using matching keys
Table Key = "PostalAddress"."PostalAddressId" and Attribute Key = ''
The DatabaseJoiner is fine, because it has an "Unjoined" output port. Plus it has some nice optimizing parameters, where I can choose to read the remote data as a local cache to compare against.
That optimizing was important, as you'll see below.
The FeatureReader is awkward because it only tells us what IS matching, and we need what IS NOT matching. So after the FeatureReader I still need a second process to compare its output against the source, probably a FeatureMerger/Joiner again.
ResultsAs mentioned, my datasets both consisted of the same 13,597 records. They would all match, so I figured it's a "worst case scenario". Let's see what I got (sorted in the order I tried them)...
MethodTimeReader/FeatureMerger11.4 secondsReader/FeatureJoiner9.1 secondsSQLExecutor/Tester1 hour, 40 minutesDatabaseJoiner (no optimization)12 minutes, 35 secondsDatabaseJoiner (optimized)9.5 secondsFeatureReader (by itself)2 hours, 15 minutesSQLCreator/FeatureMerger5.3 seconds
OK. This really surprised me. The fastest results were the ones that read all the data from the PostGIS table and processed it locally:
Read All MethodTimeSQLCreator/FeatureMerger5.3 secondsReader/FeatureJoiner9.1 secondsDatabaseJoiner (optimized)9.5 secondsReader/FeatureMerger11.4 secondsNotes:
- The SQLCreator is probably faster than a reader because it doesn't need to include geometry.
- The FeatureJoiner creates a join per match, so it wouldn't be helpful when it's not a 1:1 match
- The DatabaseJoiner was optimized to download the entire table into a cache before starting.
The worst results (the ones that put me in Agony City, as painter Bob Ross liked to say) were the ones that read the data selectively:
Selective Read MethodTimeDatabaseJoiner (no optimization)12 minutes, 35 secondsSQLExecutor/Tester1 hour, 40 minutesFeatureReader (by itself)2 hours, 15 minutesNotes:
- Here the DatabaseJoiner wasn't optimized manually, but probably did its own caching and optimization.
- The SQLExecutor and FeatureReader methods I let run for 10% of the records, then extrapolated.
So why were my instincts so wrong?
Performance TuningIn training, tutorials, and the knowledgebase, we always emphasize that reading all of your database table into FME is excessive. Performance is a measure of useful work carried out in a certain time. If you're reading and processing excess records, then that's not useful work.
However, our performance tuning article also mentions two important facts:
- Individual queries to a database are very expensive
- Best Practice is to make full use of the available system resources
The solutions I thought would be best tried to minimize use of system resources, by making thousands of database queries. In reality I had more than enough system resources to download the entire table with a single query, and process it locally.
So just how expensive are individual queries? That depends on where your database sits, how it's indexed, and what network speed you have. I was calling out to a Postgres/PostGIS database on Amazon RDS. I'm not sure what region, but my guess is Oregon.
The SQLExecutor returning a count of each matching record, took 0.5 seconds per feature. That's not an FME overhead, it's a cost in waiting for the database to return a result; and it's actually way worse than it sounds.
Note: The same overheads could also apply to writing - so check out the options for chunk size (Features per Bulk Write) and Transaction Interval in your database writers.
And how much memory did I use reading all 13,597 features at once? Not much. With the Reader/FeatureMerger FME logged a maximum of 134MB. Remember, that's both data and whatever memory FME itself takes.
Sticking in Cloners and extrapolating a bit, plus with my machine spec, I figure I can consume 5m records before getting close to physical memory limits (15m before hitting the FME virtual memory limit).
Admittedly addresses have a minimal geometry load, but that's still a pretty good amount of features that my 8-year-old machine can cope with.
SummaryTo summarize: I wasn't just wrong, I'm shocked at how wrong I was!
I did not realize quite how slow a single database query can be. Consider, there are only 86,400 seconds in a day. With overheads like above, I could easily spend all day waiting for the database to process just 100-200,000 queries!
I hadn't considered before that a bad design can perform better simply because it's being greedy with its use of resources. Finding that out was... well to quote Bob Ross again:
We don't make mistakes; we have happy little accidents!Obviously, your mileage may vary. But this showed me that even when you design for efficiency, you need to consider less efficient methods. So the two takeaways today are:
- Be bold with your use of system resources.
- There's no point in having GB of memory available and not using it
- Be wary of database queries.
- A single query - multiplied over lots of features - can be a crippling bottleneck in any translation
So there you go.