

Hi,
I have a huge dataset to write in text files.
Each line has a file_id and an identifier. This identifier is not unique and can be repeated.
I must write everything in a maximum of 100 files.
I must write a maximum of 250 lines per file.
To do that, since each file must have an id, I thought I could simply use the file_id in the file name when writing.
Here is what I did :
- I use a Counter to add a _count attribute to each line.
- I divide this _count attribute by 250 to create the file_id attribute.
- I use AttributeRounder to round the file_id.
- I write the text files with a FeatureWriter and by setting the name : "file_@Value(file_id)".
Once I've done this, I can write a maximum of 250 lines in each text file.
However, all lines with the same identifier must be in the same file, and with just the steps above, that's not the case.
So I thought about :
- using Agregator to group by the identifier and create a list of file_id.
- using ListRangeExtractor to extract the maximum file_id in the list.
- using AttributeManager to set file_id with the maximum.
I thought I was done with this, but then I realised that, since the file_id was already computed, I was just adding more lines at the beginning of the next text file. So I will have more than 250 lines...
What should I do since I can't use loops in FME ? Is there a more simple way to do things ?
Here is an image to help you understand, in case my explanations are not clear :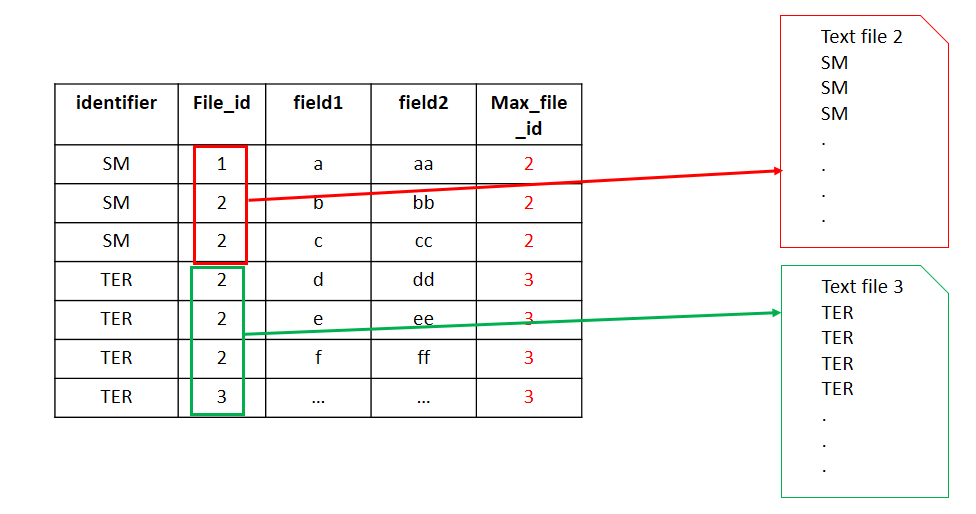






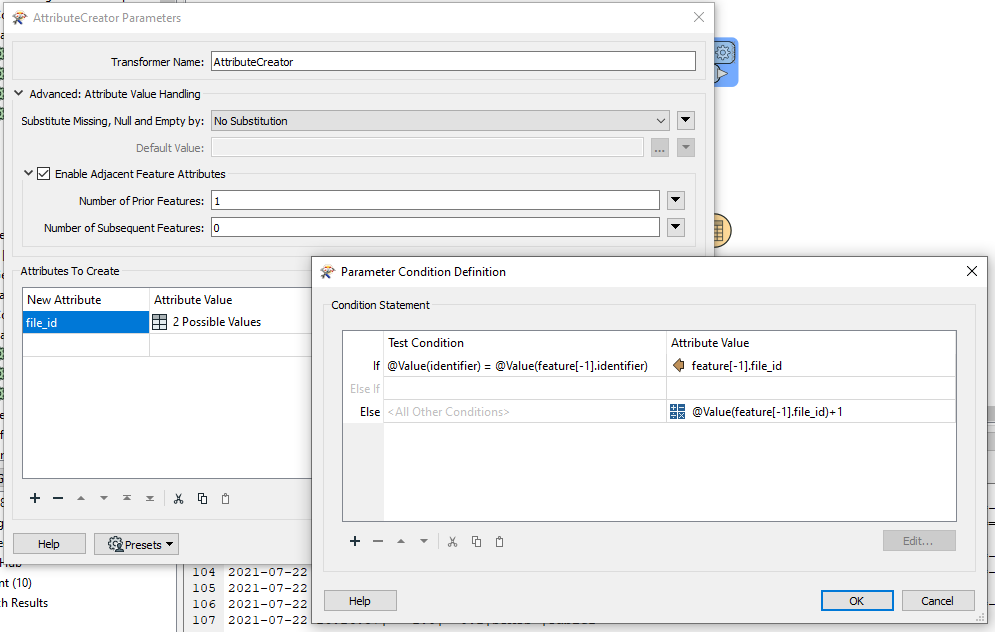



 Special thanks to
Special thanks to