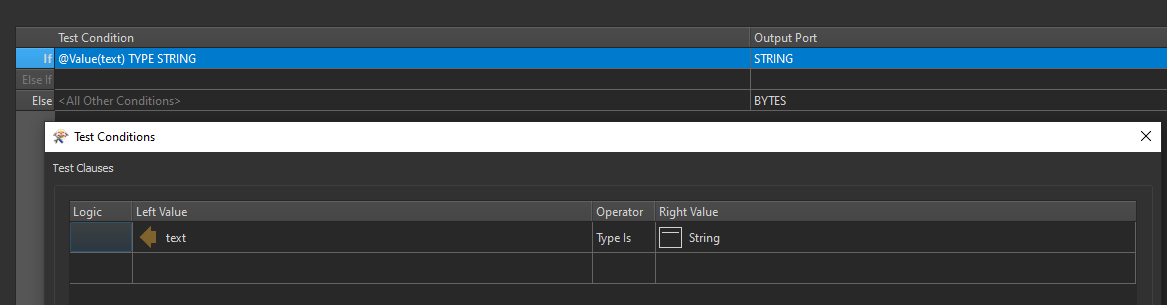
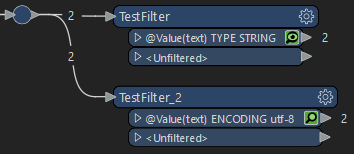
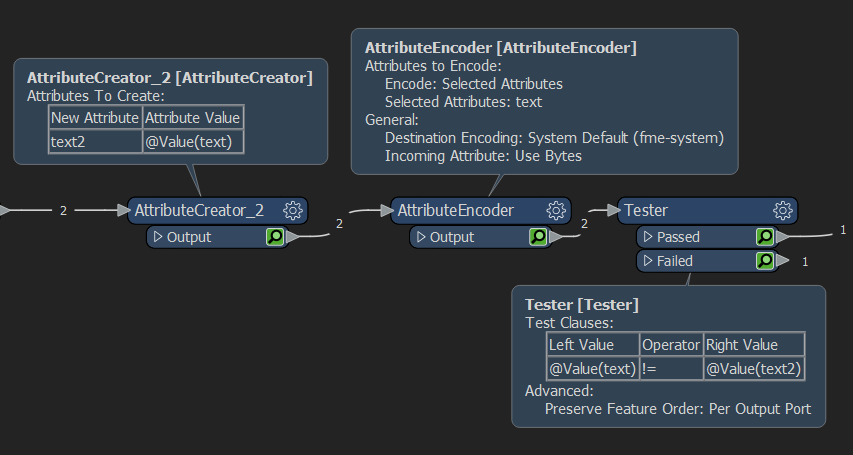
Say I have the following data;
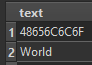 for which I can see the following information in the Feature Information window;
for which I can see the following information in the Feature Information window;
feature 1; text (bytes): 48656C6C6F
feature 2; text (string: UTF-8): WorldIs there a way that I can filter the features on the basis of the indicated data type (i.e. 'bytes' vs 'string (UTF-8)'?