


This question is similar to one already asked below, but I couldn't crack the answer: https://community.safe.com/s/question/0D54Q000080hAQuSAM/css-selcetors-in-html-extractor?t=1603847778190
I would like to take the table as displayed in the xlsx example (mock up of a HTML table on a webpage), and force the values into attributes on a row per ID basis, to be able to construct an easy to use list of IDs with their associated attributes.
The tables (there are many across different URLs) are structured as in the 'HTML Table code example' (one table per ID) and I am having trouble trying to isolate the values of the associated attributes (in bold in the xlsx table example). The attribute names are always the same and in the same order, but not necessarily on the same row numbers everytime. I tried isolating by using the _element_index (using HTML Extractor and ListExploder) but these are not consistent across all tables (as attrbutes such as location can have multiple values), so i need to be able to recognise where, for example, td = ID and retrieve the next td value, which would be the ID value. Etc
Hope this makes sense, i'm very new to HTML and CSS selectors! Thanks FME team.
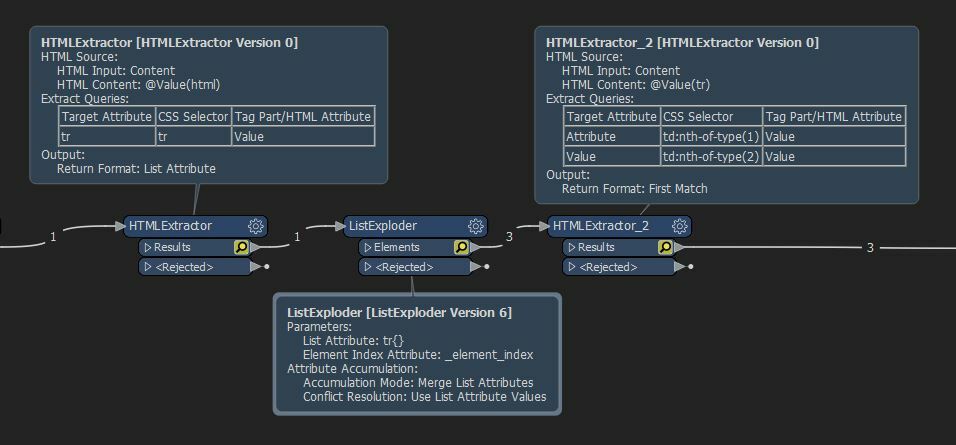 The location values will probably need some further tidying up but that should be straightforward
The location values will probably need some further tidying up but that should be straightforward

