@Takashi Iijima
I need to make a connection to an API with FME.
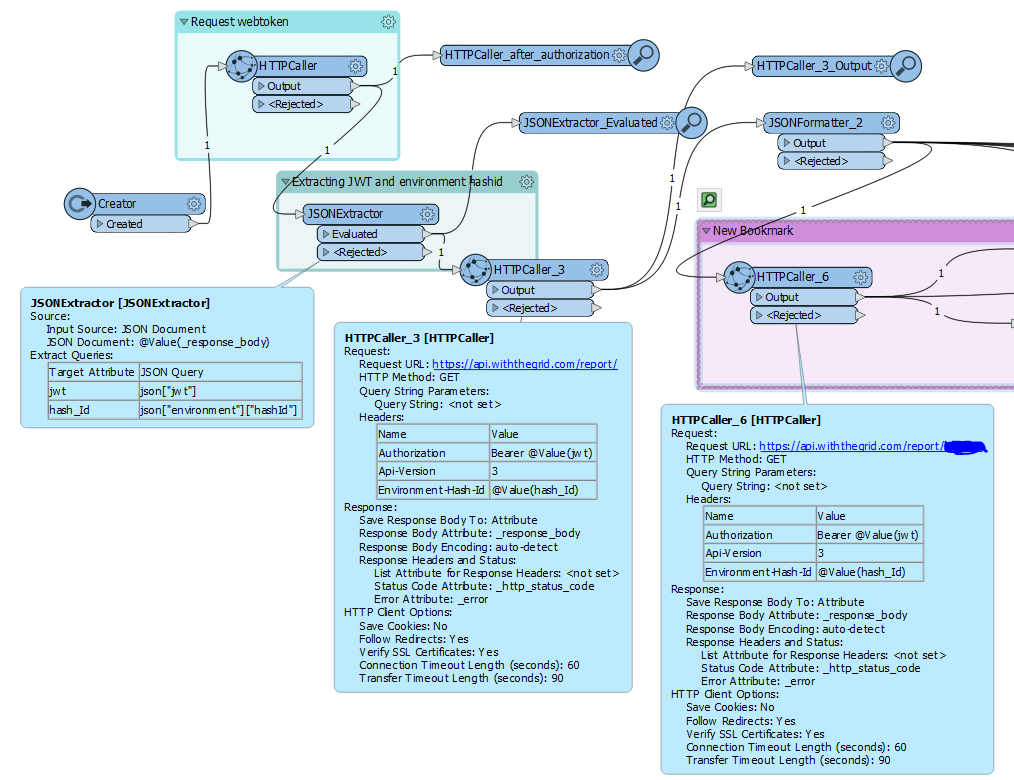
This is a 2 step verification process, where I first have to receive an json webtoken through the 1st HTTP caller (see image). With that webtoken, I thought I was able to get all the available reports through the 2nd HTTP caller, to then move on to extracting data from a specific report (3rd HTTP caller). For the time being I just manually added the report hash id to the request url.
Apparently, I don't get all the reports through the 2nd caller, and I also don't get all the available data in that specific report after implementing the 3rd caller. I only get a small portion of data after implementing the 3rd caller. (for example only 6 measurements inputted by the same user instead of all available updated measurements)
It was suggested to me that I need to apply loops? How does this normally work in FME? I'm stuck, and using APIs is new to me.
This is the link to the API documentation