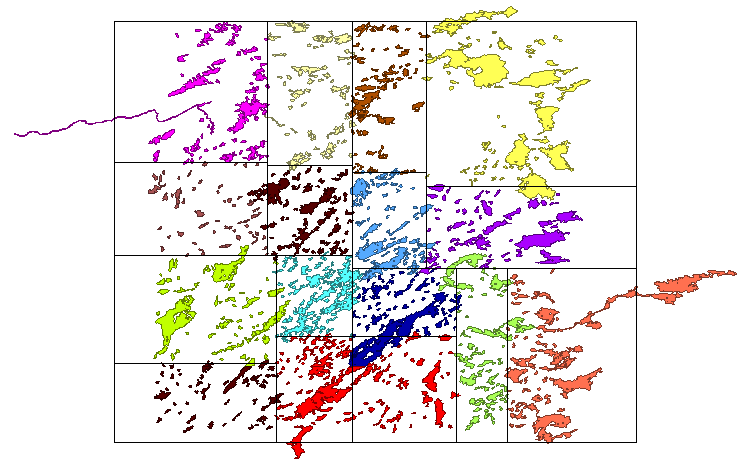
You can specify the maximum N (number of points per cell). If the number of source points was equal to N x 2^m (2 raised to the power of m; m > 0), every cell will contain exactly N points. Otherwise, cells contain almost identical number (equal to or less than N) of points.
See this workspace example containing a PythonCaller: irregular-grid.fmw (FME 2017.0.1)
# PythonCaller Script Exampleimport fmeobjectsclass FeatureProcessor(object): def __init__(self): self.maxNumPointsPerCell = 20 # Maximum number of points per cell self.features = [] # list of (x, y, feature) def input(self, feature): if feature.getGeometryType() == fmeobjects.FME_GEOM_POINT: coord = feature.getCoordinate(0) self.features.append((coord[0], coord[1], feature)) def close(self): if self.features: self.cell_id = 0 xs = sorted([x for x, _, _ in self.features]) ys = sorted([y for _, y, _ in self.features]) self.distribute(self.features, xs[0], ys[0], xs[-1], ys[-1]) def distribute(self, features, xmin, ymin, xmax, ymax): if features: if len(features) <= self.maxNumPointsPerCell: for _, _, feat in features: feat.setAttribute('_cell_id', self.cell_id) self.pyoutput(feat) coords = [(xmin,ymin),(xmax,ymin),(xmax,ymax),(xmin,ymax),(xmin,ymin)] cell = fmeobjects.FMEFeature() cell.setGeometry(fmeobjects.FMEPolygon(fmeobjects.FMELine(coords))) cell.setAttribute('_cell_id', self.cell_id) cell.setAttribute('_count', len(features)) self.pyoutput(cell) self.cell_id += 1 else: n = len(features) // 2 if (xmax - xmin) < (ymax - ymin): features.sort(key=lambda f:f[1]) ymid = (features[n-1][1] + features[n][1]) * 0.5 self.distribute(features[:n], xmin, ymin, xmax, ymid) self.distribute(features[n:], xmin, ymid, xmax, ymax) else: features.sort(key=lambda f:f[0]) xmid = (features[n-1][0] + features[n][0]) * 0.5 self.distribute(features[:n], xmin, ymin, xmid, ymax) self.distribute(features[n:], xmid, ymin, xmax, ymax)