Hello all,
I think this is the right place to get answer to my question..
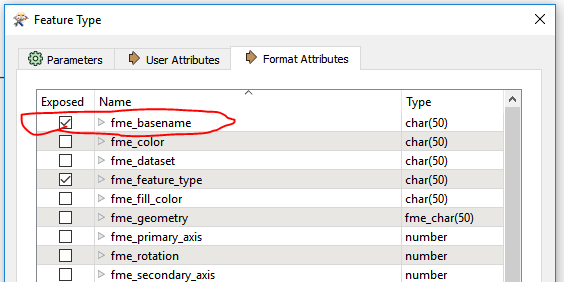
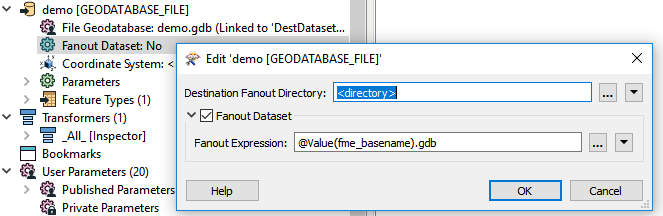
I have a batch of Revit files converted them in to .RVZ using FME Exporter and i need to convert them in to .GDB files by using FME Desktop .
I have a knowledge creating them as a single file (RVZ----GDB)
But am looking for Batch process to convert .RVZ files to .GDB files.
Please help me out ..
Thanks in advance ...