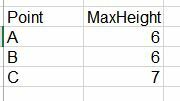I have a point feature containing different entries per point (multiple measurements on different heights), and i want to aggregate my attribute table in a way that only one entry per X,Y-point exist.
The final entry should thereby only contain the maximum values of all measurements per points.
I tried using the Aggregator tool, however, I was unable to keep the maximum values, since the only implemented functions seem to be average and sum.
I think of using my own python script withih a PythonCaller, but it did not work either (I know it must work , but I am pretty new to both FME and Python and just did not succeed).
Any help much appreciated!
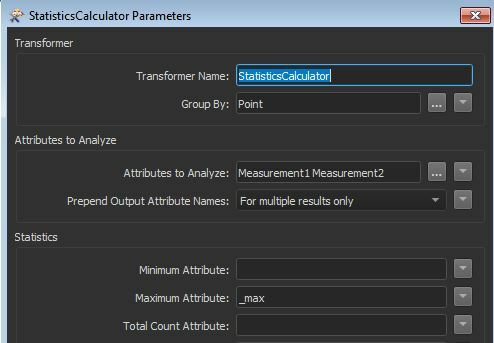 You'd end up with something like this from the Summary port
You'd end up with something like this from the Summary port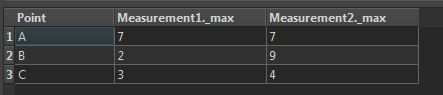



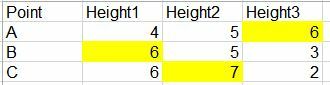 and you're aiming to get to something like this?
and you're aiming to get to something like this?