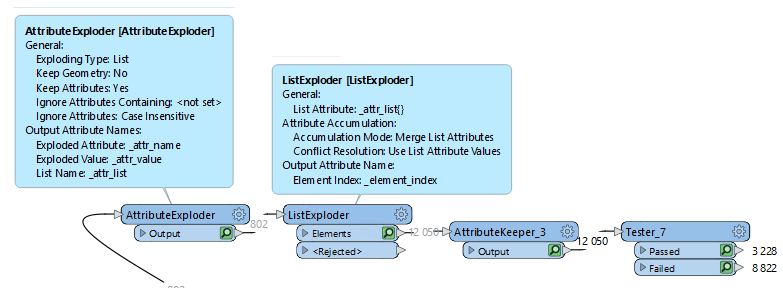
Hello Community,
I have a question and looked for answers but didn’t find it yet.
It must be simple for someone but I have not yet figured it out. I tried attribute transposer, aggregator etc
I have a table with a feature which has an ID here shown as Feature 1,2,3 and multiple columns with values for each month of the year.
It is like so:
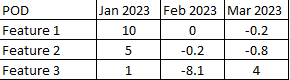
What I yould like to get is the following:
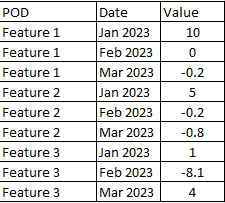
In the end I need a row for each column corresponding to the feature it is refering to.
I found some sort of a possibility but it it very “manual” an inelegant in FME as I have to create each month manually and associate a date etc.
If someone has a better idea, I am very interested about it. It would help me in the long run as I may have a wrong approach to transposing data with FME.
Many thanks to all the contributors.
Best regards, Thomas