



I'm having a bit of an issue with text fields being truncated, and I can't figure out why...
The fields are all text fields of varying length, with writer definitions copied from reader, and for some reason they all come to the writer truncated to 4 or 5 character's length?!
This is how the read attribute info looks (reader is GDMMAPPERQUADRI):
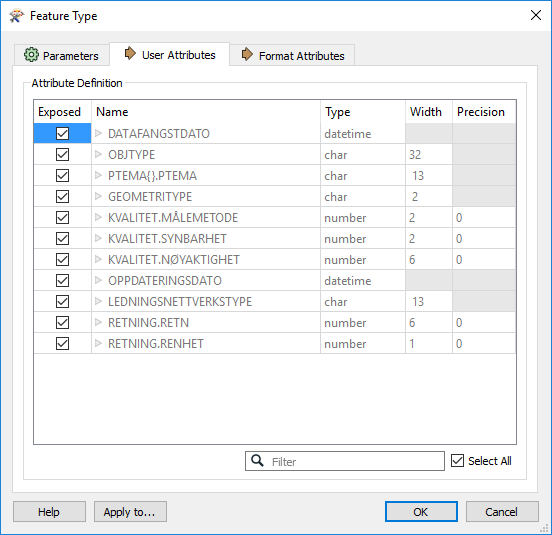
...and here's the writer (Writer is GEODATABASE_FILE):
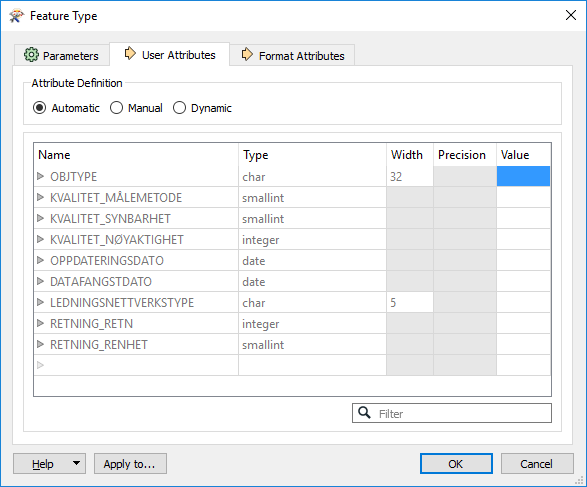
Note now the attribute LEDNINGSNETTVERKSTYPE is changed from length 13 to length 5. This behaviour seems consistent for most attributes, but not all (like OBJTYPE in the example).
I tested a different writer, just to see (ESRI Shape) and it's the same there, also doesn't matter if I port directly from reader to writer or if I mess round with the data inbetween. Is it the reader that "sends the wrong signals", despite the correct attribute definitions being listed?








