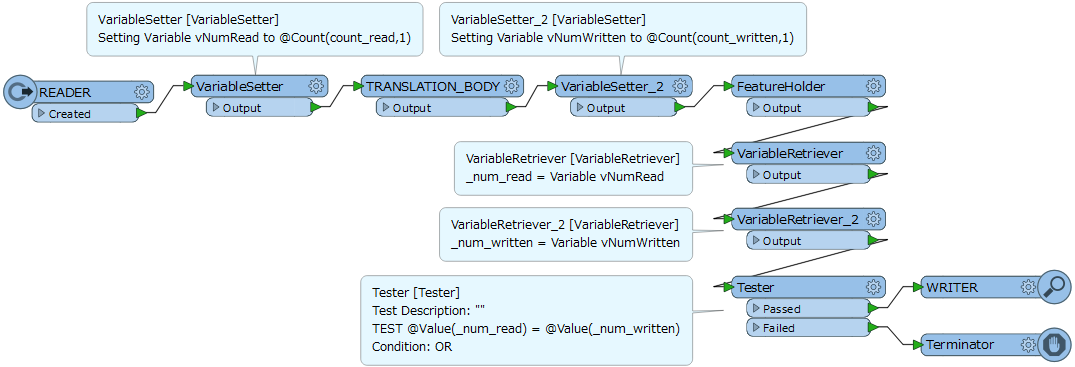
I'm building quite a lot of flows where the amount of input features should always be the same as the amount of output features. During the processing of the data a lot of transformers merge, delete, split, and aggregate the data but in the end it should always result in the same amount of features as i started.
I now use an UniqueValueLogger to list all the ID's in between and then compare it and at the end i do a manual check to see if the correct amount of features are written to the writer. But i was wondering if this could be tested with the tester and if it does not match can stop the translation raising an error that the input data is not correctly formatted.