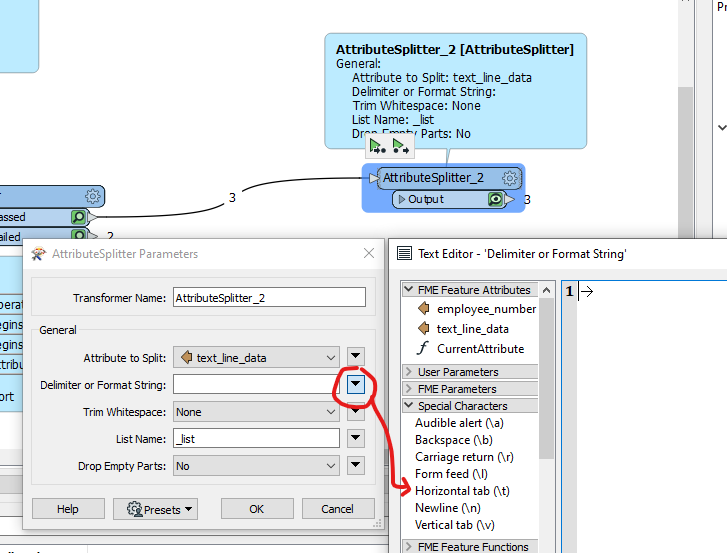
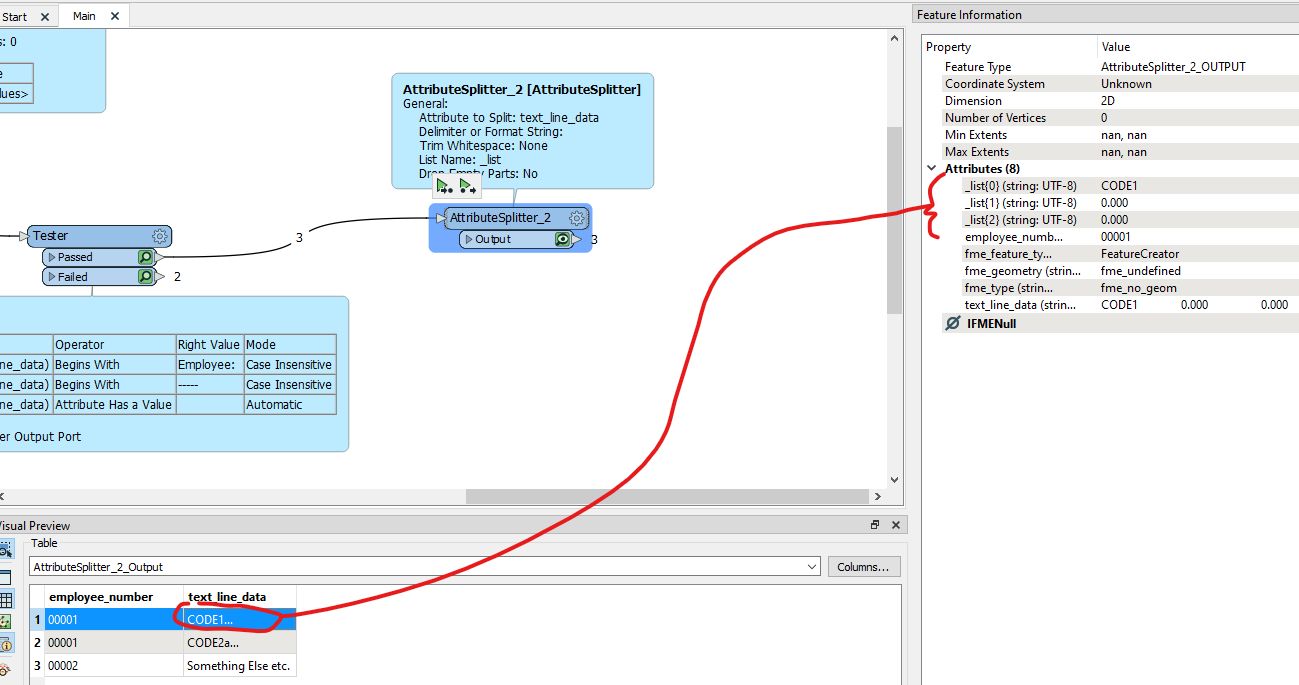
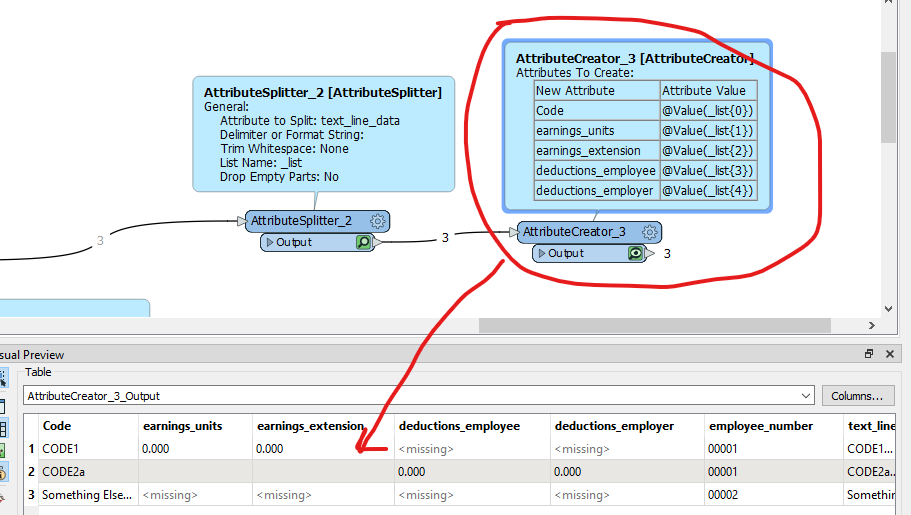
Hello,
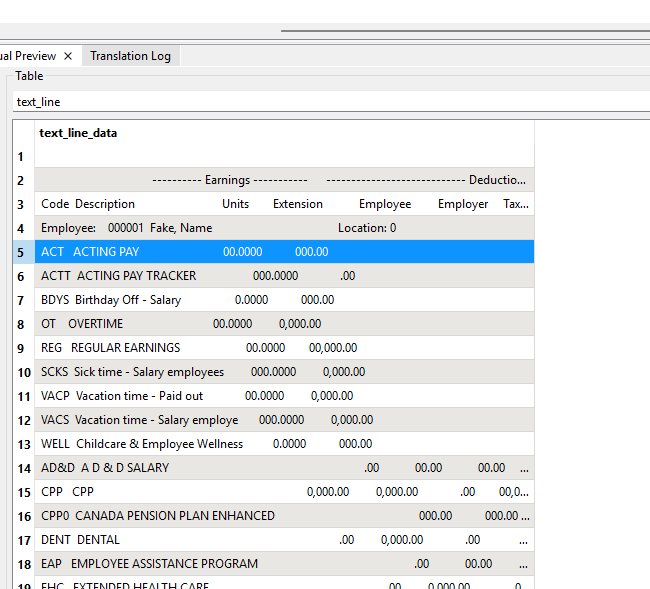
I have a pdf report that I need to parse out. I can read it and create a line by line list. It has a line with employee code/name, then subsequent lines with codes and their values associated to the employee. Here is a sample of the report and then what it looks like when it is read in.
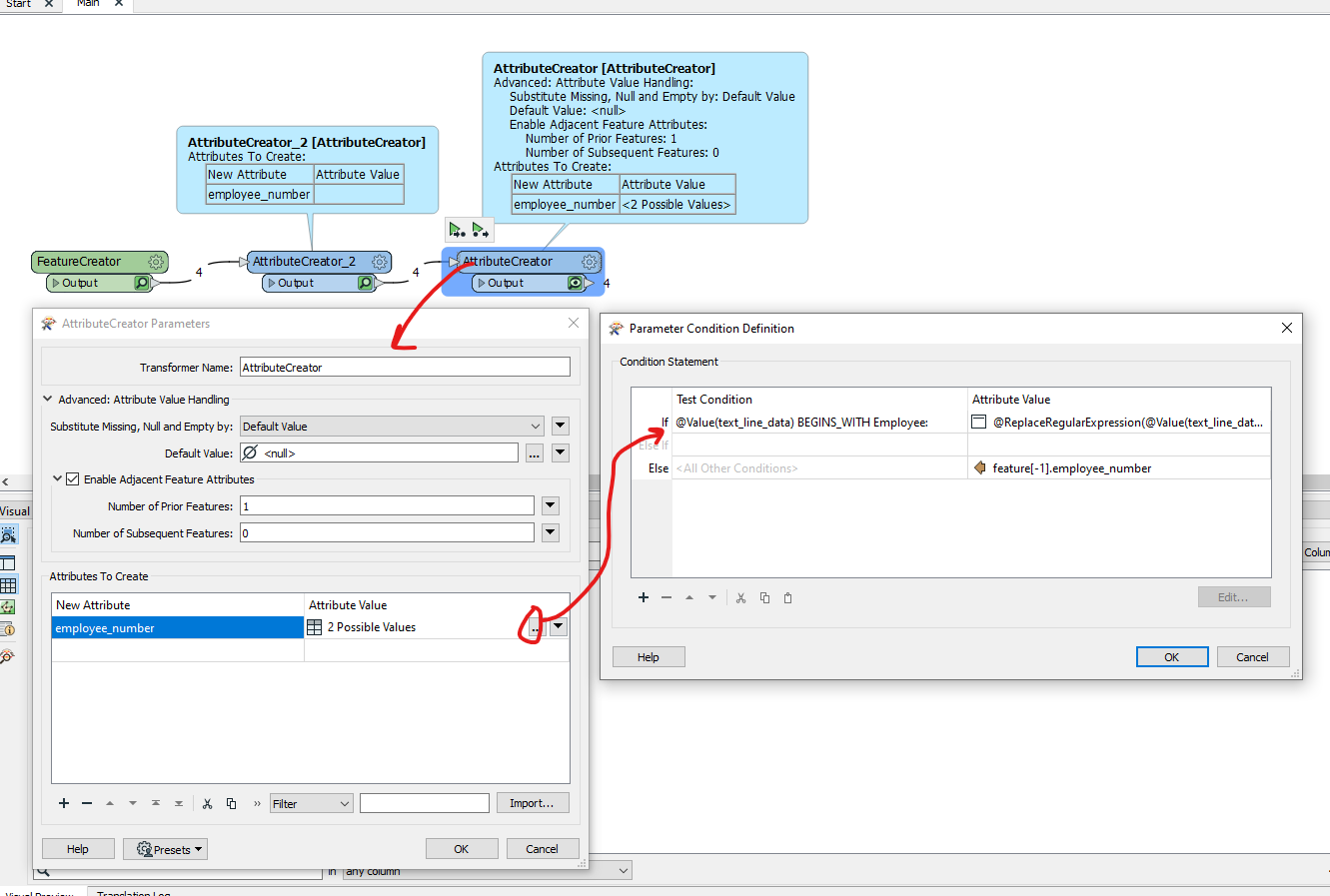
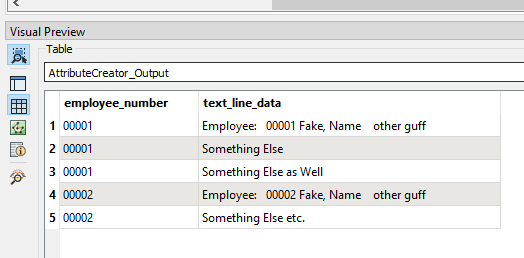
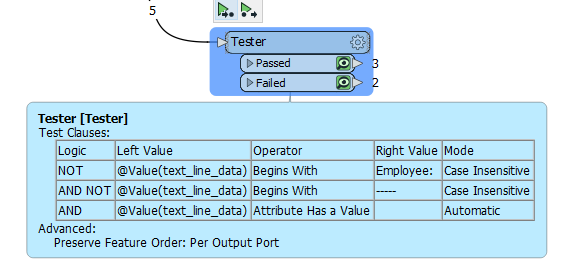
I can get it split nicely into rows/columns/attributes no problem. My issue is that I dont know how to break it up in each employees portion and add the employee number to each row.
There would be a few hundred employees.
So in the end I want to be able to spit out a table that has the columns:
Employee num, Code, Description, units, extensions,etc
I am very new to FME and just struggling to get it figured out. I dont know if I should be using some kind of loop, python code, aggreator etc.
Any help would be greatly appreciated!