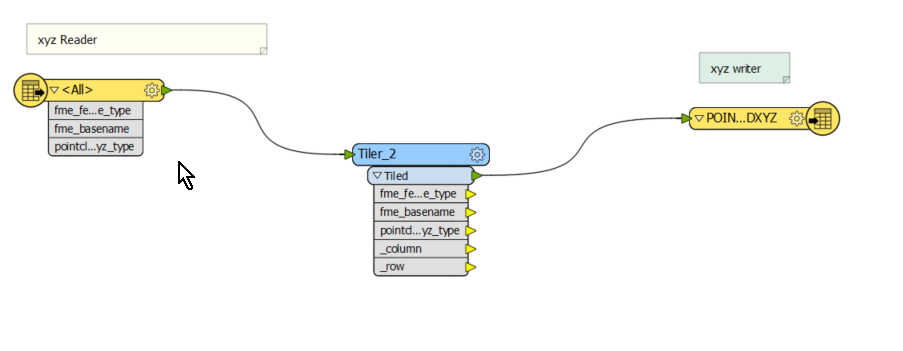
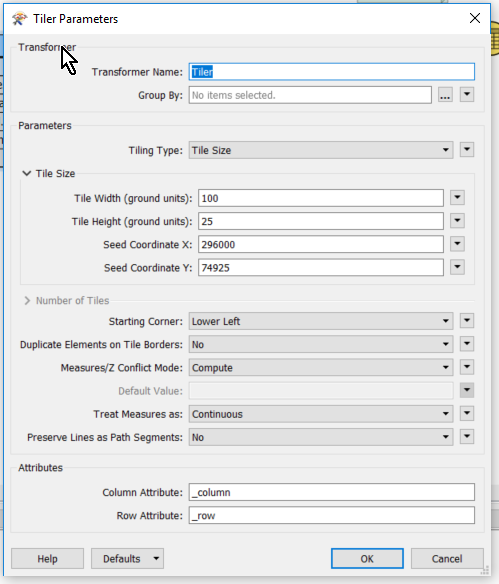
I have an ~80gb file that i need to split into around 15 files geographically into 25x100 strips.
https://knowledge.safe.com/articles/1100/tiling-point-cloud-data.html is helpful but FME will still read the whole file in one go. i only have 16-32GB of RAM (depending on computer im using) and so the computer will fall over. how can i split this file geographically and get around FME reading the whole file in one go?