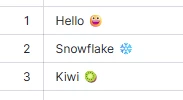
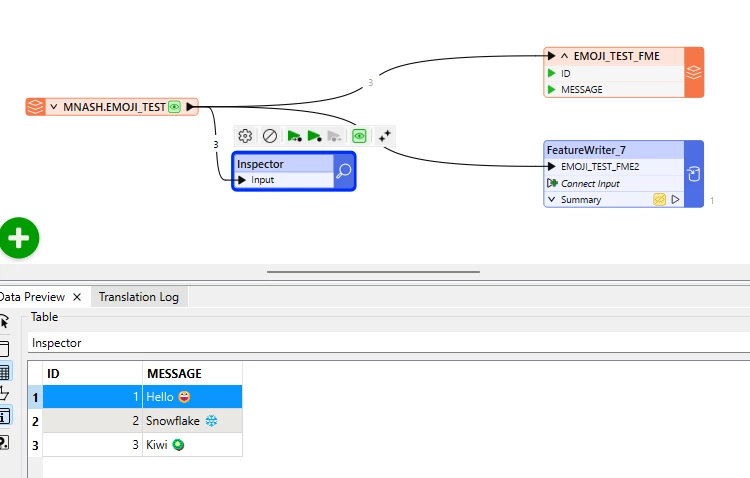
I have encountered an issue where using a Snowflake writer will either cause errors or corrupt data if the text field contains emoji characters.
This is occurring with FME Form 2025.2.3.0 on Windows 11.
If I am writing to a VARCHAR column in Snowflake, the emoji characters will be corrupted but the field will write. If I am writing JSON to a VARIANT column, the workspace will fail with an error.
In the past I have just let this issue go because I have been writing to VARCHAR fields. Now that I’m writing JSON to a VARIANT, I need to find a better solution.
Although I believe FME 2025 and Snowflake are both using UTF-8, it looks like it is getting converted to something else somewhere along the line.
The easiest way I have to test this is to create a Snowflake table:
create table mm_temp_utf8_test (text_col varchar, json_col variant);Then I can use a SQLExecutor.
If the SQLExecutor just populates the VARCHAR column, it will succeed but the data will be corrupted:
insert into mm_temp_utf8_test (text_col, json_col)
select column1 as text, parse_json(column2) as json
from values (
'This is a test: 😂😂: FME',
'{"item": "value"}'
) as valsThe corrupted data looks like this:
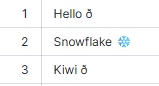
This is a test: ðð: FME
However, if I also have emoji in the JSON, the command fails:
insert into mm_temp_utf8_test (text_col, json_col)
select column1 as text, parse_json(column2) as json
from values (
'This is a test 😂😂',
'{"item": "value", "item_2": "😂😂😂😂"}') as vals
Both of these bits of SQL work when run directly in Snowflake.
I’m using a SQLExecutor here but my main problem exists in a FeatureWriter and SnowflakeWriter. This is not a problem when reading the data as I can read the emoji in a FeatureReader, SnowflakeReader and a SQLExecutor.