I have a set of nodes on this format:
<node lat="56.07686365" lon="12.11483240" id="800000002" changeset="1" timestamp="2017-09-10T20:50:35.826Z" version="1">
<tag k="ActiveFrom" v="1900-01-01T02:00:00.000000000Z"/>
<tag k="ActiveTo" v="3000-01-01T01:59:59.000000000Z"/>
<tag k="ProductionPointCategory" v="4"/>
</node>
When I read them in to the OSM reader as basic nodes, I get a list of tag{}.k and tag{}.v. I want to do some light filtering on this data, mainly checking if they exist in another dataset.
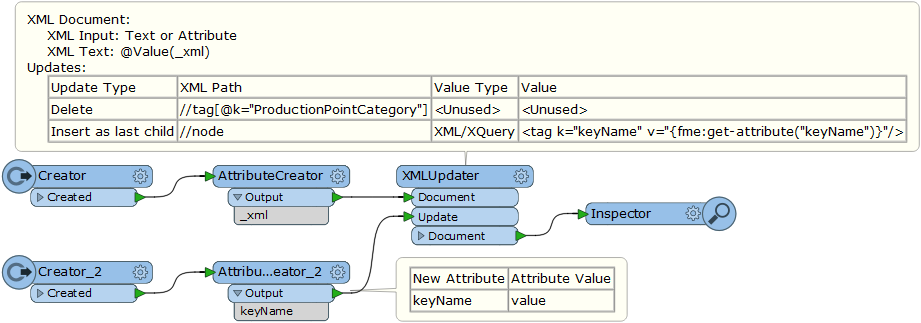
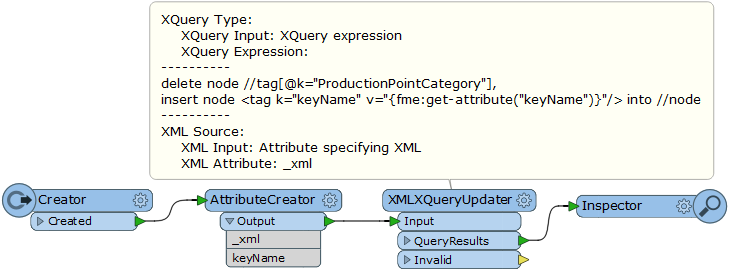
Thereafter, I want to write them back to the same format that they came from. However, if I just connect the reader straight to the writer, it doesn't write out any of the content of the tag-list. I have to expose all the attributes that I want to be written, which seems like a backwards idea since the information is already there in the key-part of the tag-list.
Is there a way to get the writer to write the contents of the tag-list, without me manually exposing the attributes? There will be nodes of different forms, so "hard-coding" this via the attributeExposer isn't optimal.