
")

I would like to be able to parse a response from the Bentley OpenGround REST API, and am getting somewhere but not far enough!
I can use a mixture of attribute exposer and JSONFragmenter to get some information out, but it never quite looks like the table i want. i will be doing multiple queries over the coming months into this api, and will have a different number of columns each time, so cant parse through each data record based on the number of columns i want in that particular query!
I can get to the point where i have a feature for every feature in the database, and then i have a _response_body which i need to parse further. i can keep parsing it through jsonfragmenter, and i end up with a jumbled mess where columns are names wrong and the colunn information i want is in the wrong part of the table. it is a simple structure, such as “DataFields” “heade” for column name and “value” for data itself. i will add some screenshots to aid in query. any help would be greatly appreciated!
Thanks
Ben
screenshot showing raw response for one attribute:
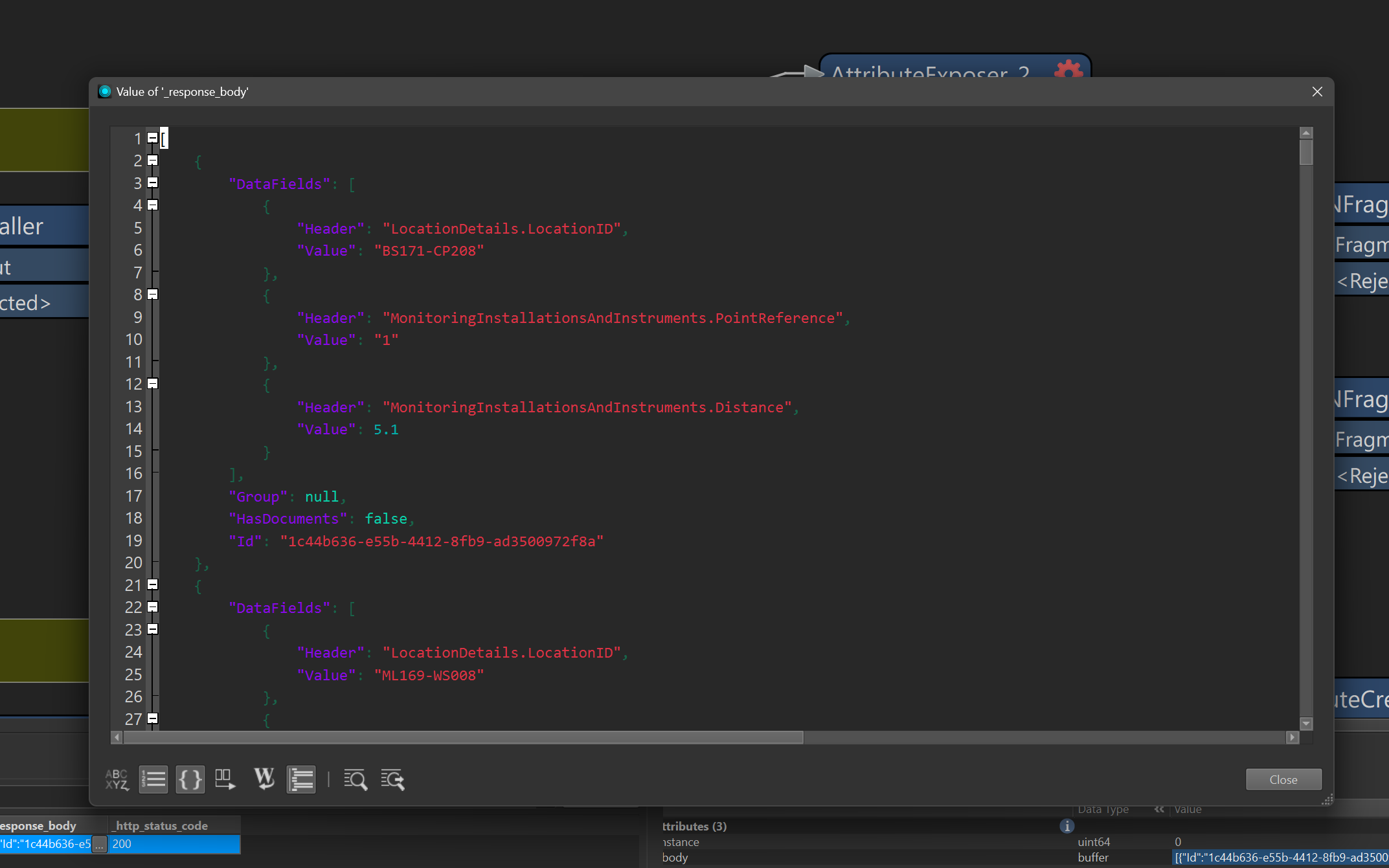
which i can parse with the json fragmentor, to get this,
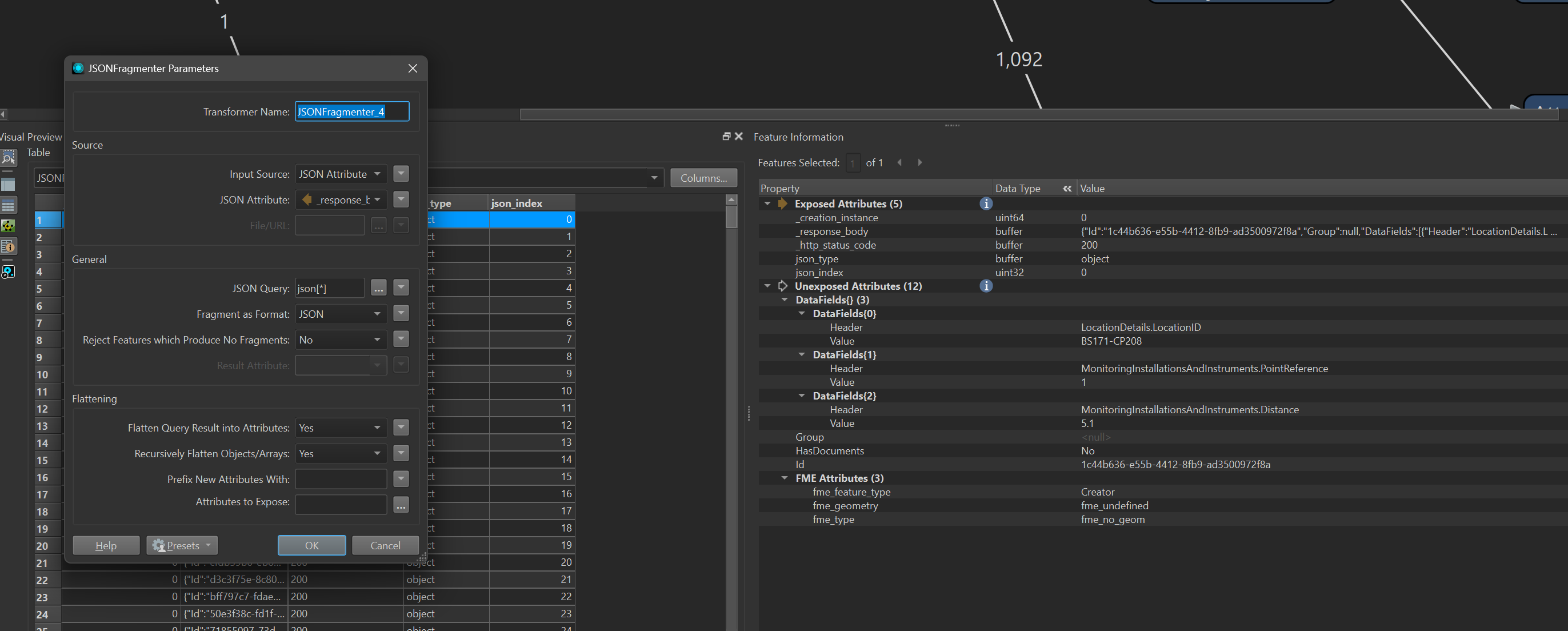
and then i try to expose the attributes as follows, but the results are the wrong structure - columns like LocationDetails.LocationID with a value of “BS***” etc



