


Hi,
I have an excel spread sheet that i have to read and load into a database table. The structure of the excel sheet is different from that on the database. Sample screen shot of the excel spread sheet is seen below. Columns J-S are county names, and the values associated with it are the cost for each county.
I need the 10 county column names loaded as values into COUNTY_CD column in the database and its associated county cost value loaded into database column COST_PER_SQFT.
So, for every row in the excel spread sheet I will have 10 rows in the database and each row represents data for each county.

The database columns and the values to be loaded should like below
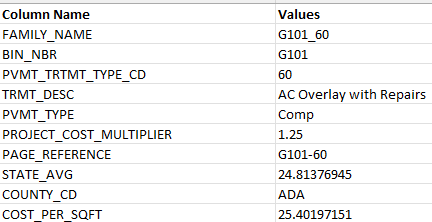
I had looked into several post that does transpose of columns, pivot tables etc, but I couldn’t find a solution that works for me. Any help is much appreciated!
Thank you,
lsugumar.

