


Last week I was contacted by a colleague to process a text based dataset that reminded me of something I had seen in the past for Fortran based datasets.
In particular, the text based dataset looks somewhat like a CSV dataset, only now columns are separated by a fixed width. See below for an example of how it looked:
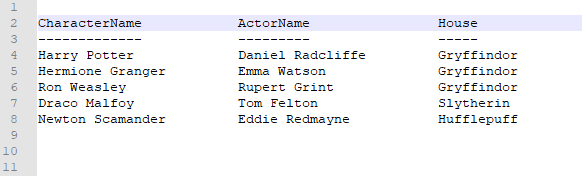 I was wondering if there is maybe already some type of reader that can deal with such type of data?
I was wondering if there is maybe already some type of reader that can deal with such type of data?
Of course, if you get such a dedicated dataset, you can use a text_line reader, cut/split the text line into separate features (based on the known width (e.g. using a '#s#s#s' format string in an AttributeSplitter, see third example on the documentation page)), and then using e.g. an AttributeTrimmer to remove excessive whitespace.
However, this method needs to be configured for each individual dataset, so I was wondering if there was maybe already a tailored made reader that could do this (by first automatically detecting the column widths).
Out of curiosity I created a workspace myself that could deal with files like these a bit more dynamically (using the header line to detect the widths of the columns). But it's not that clean and requires manual exposing of the attributes at the end. Also it assumes the headerNames don't contain (white)space characters, and in this case also requires manually removing the header/data separating line (such a line was not present in the dataset I encountered earlier, so I considered this as a manual step). Nevertheless, see the attached workspace.




