Hi,
I try to import an Excel file in a Postgres table.
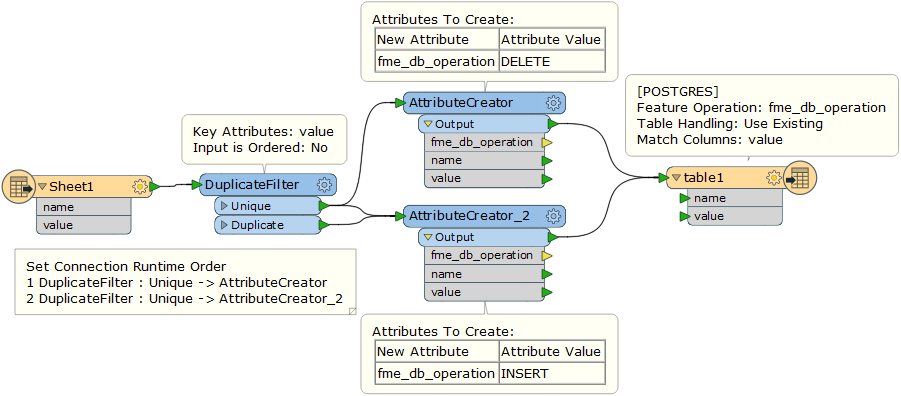
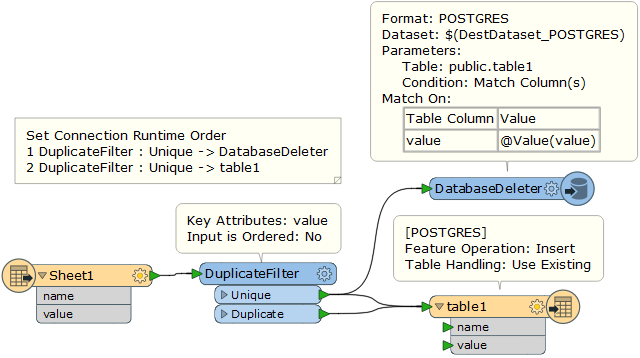
But before inserting the rows of the Excel file, I have to delete all records in the destination table where the values of a column from Excel file are matching the values of a field in the Postgres table.
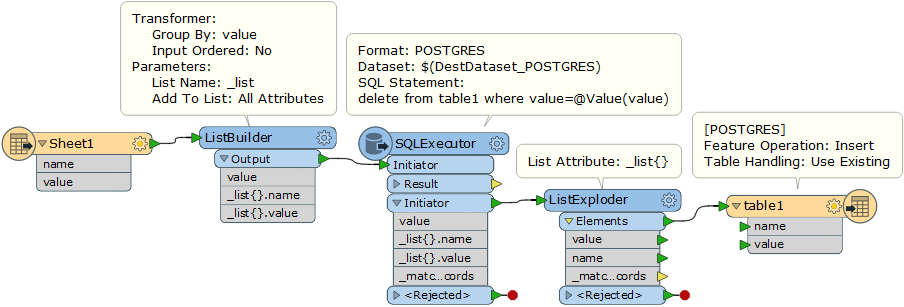
I achieved to perform the delete operation with an Aggregator transform that performs a groupby operation on the Excel column and a SQLExecutor transformer that deletes in the destination table all records whose values are matching one of the groupby values.
That part works fine.
But now, I don't find out how to plug after this the insert operation on a Postgres writer.
Because the SQLExecutor returns only the groupby values from the initiator.
I don't think I can use a DatabaseUpdater transformer with fme_db_operation for this context.
Thanks for any help.