
We have some text fields that shouldn’t have any UNICODE characters. Turns out at least one has snuck into the data. Is there a way to Test to find UNICODE characters and then remove them?
FME 2022.2.3

 +10
+10We have some text fields that shouldn’t have any UNICODE characters. Turns out at least one has snuck into the data. Is there a way to Test to find UNICODE characters and then remove them?
FME 2022.2.3
Best answer by bwn
Since FME uses a PERL implementation of RegEx, then could use StringSearcher with RegEx to find where there is a string that has a match to a non-ASCII character, and the character positions.
RegEx Pattern looking for is [^[:ascii:]]
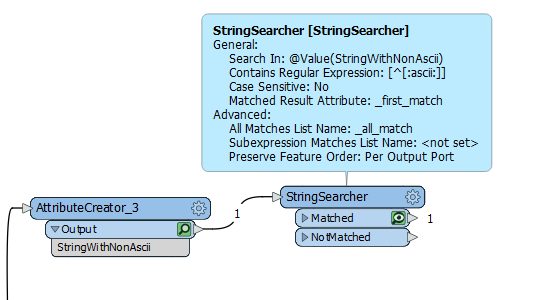
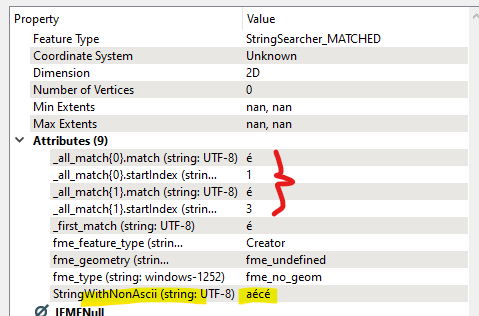
Gives
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.



