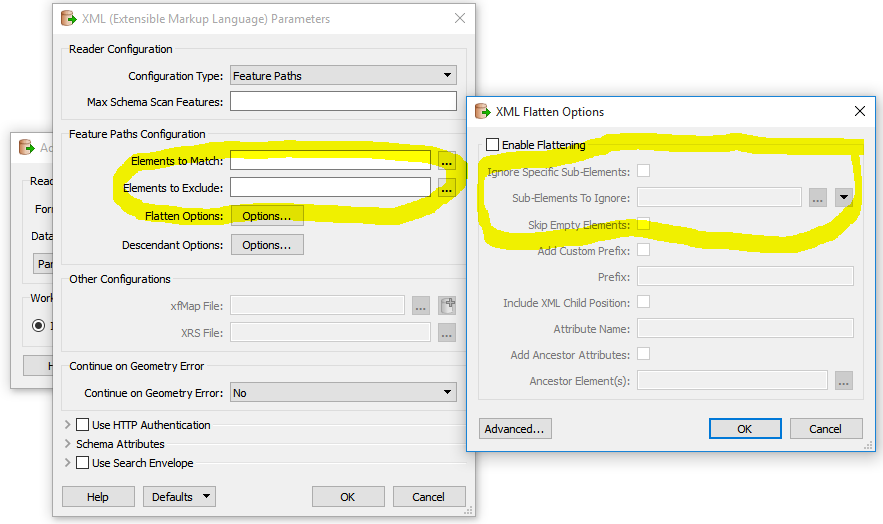
Hello, I have an element which contains child elements but I only want to extract the text of the element ignoring all the child elements.
Here is my example :
<list_item>
<paragraph>A wreck exists in position
<location>America>
</location>
</paragraph>
</list_item>
What I would like to extract is A wreck exists in position.
Usually I use the Attribute Exposer but in this case it is not workingbecause the closing tag of the paragraph is after the location.
What transformer should I sue in this case?
Thanks for you help.