Hi,
If possible could someone answer these general Point Cloud Questions, apologies if they are obvious?
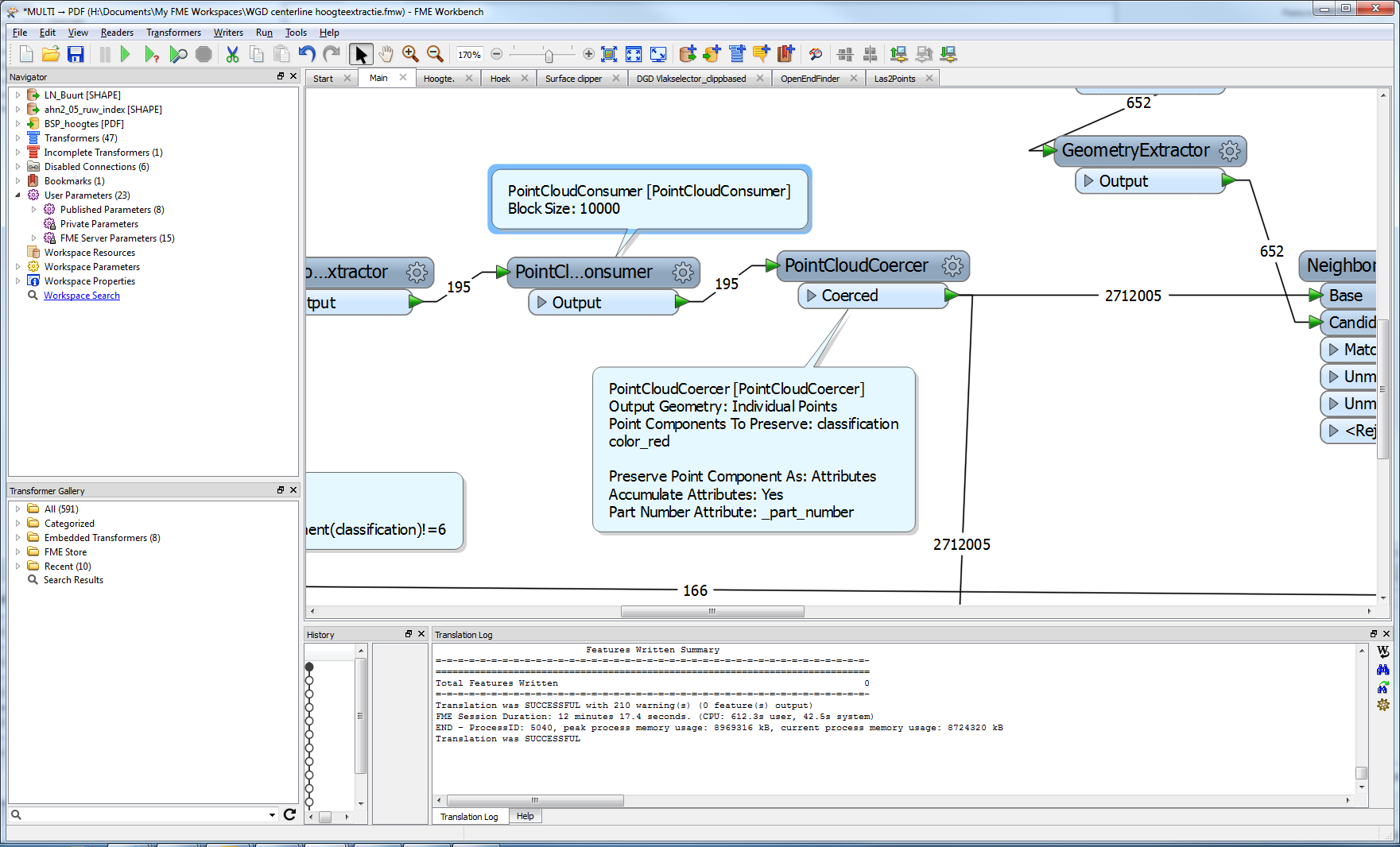
1. What does the PointCloudConsumer actually do? It is effectively acting as a valve which restricts the maximum number of points (as specified within the block size) being read in at any one time? If this is the case, then I assume it is used to ensure that the downstream workbench processes are not overwhelmed by the size of point cloud points? However, I assume that the block size means that the whole point cloud data will be read, but effectively it is read iteratively, rather than in a single hit. If it it not doing any of these things then what does it actually do?
2. Does encoding a LAS file as a blob using the PointCloudExtractor pretty much only change the encoding; but not really ‘compress’ the data in terms of size. I have a LAS file which is about 18MB in its native format. I have read it into FME and then used the PointCloudExtractor to convert the file to a blob. I have subsequently written this to a SQLite table as a blob data type. The resultant SQLite file is about the same size, is this right? (I naively imagined for some reason that the blob would have a smaller file size. I suppose that there is no reason why it should.) Therefore, is there a way to ‘compress’ the data during the conversion and writing but without degrading the data? Namely, so that I can read the SQlite table at a later date and then use the PointCloudReplacer to convert it back to a ‘normal’ point cloud but of the same original data resolution? (Essentially, I wanted to encode loads of LAS files as blobs and store them in an SQLite database, but I think the SQLite table will still be too huge.)
Thank you in advance,
Rob