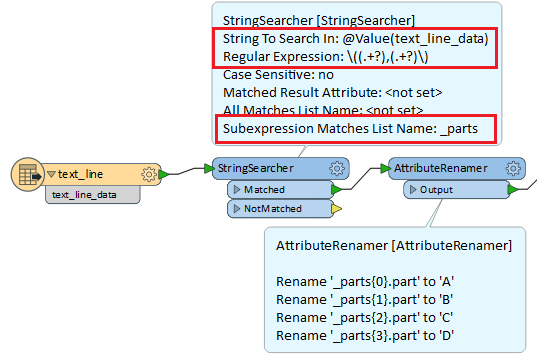
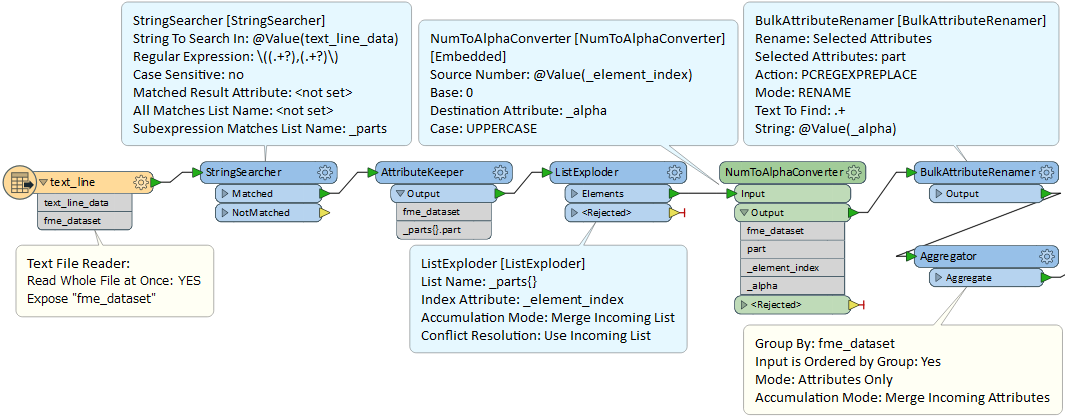
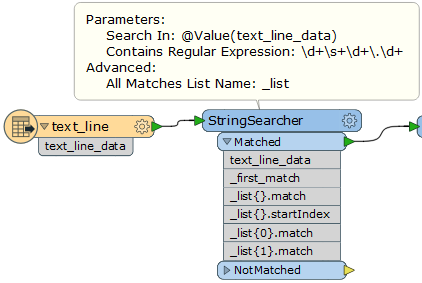
Hi FME experts,
I have a number of text files that looks like this (attached). I would like to extract the numbers and store them into different attributes to process them further.
A 468832.92042276752
B 7175381.1634021383
C 2829
D 388
What is the best way to approach this?
So far, I tried unsuccessfully using attributesplitter, substringextractor
I tried wresting with regex
For instance, the following expression returns
\\((.*)\\,
everything in between the first ( and the last , but how can I extract each string separately?
Many thanks in advance.
!table !version 300 !charset WindowsLatin1
Definition Table File "a2.jpg" Type "RASTER" (468832.92042276752,7175381.1634021383) (2829,388) Label "Pt 1", (468991.81894034828,7175225.3923977558) (4127,1684) Label "Pt 2", (468917.96947360213,7175142.166946603) (3520,2370) Label "Pt 3", (468878.98707272188,7175056.807626294) (3195,3063) Label "Pt 4", (468691.66407155019,7175209.742227288) (1660,1784) Label "Pt 5", (468758.97137093107,7175297.6046385625) (2221,1071) Label "Pt 6" CoordSys Earth Projection 8, 116, "m", 153, 0, 0.9996, 500000, 10000000 Units "m"