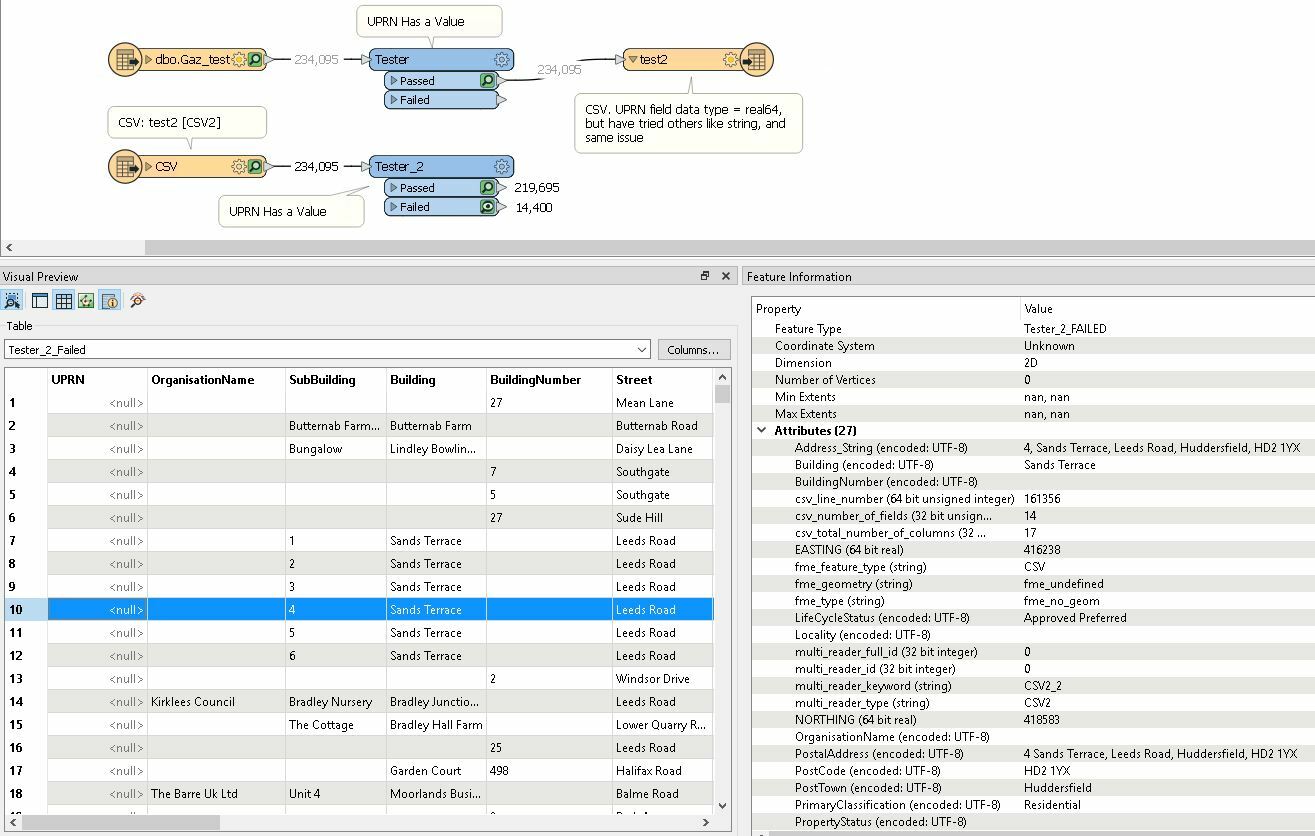
Have FME Desktop 2020. It turns out that writing UPRN's into a CSV doesn't work for values above 99.999.999. Have tried all data types in the writer (real64 is the one that FME sets automatically, but have tried String, int64, etc..). Nothing works.
Can somebody help me please?
First capture is the output before writing csv (upper workflow):
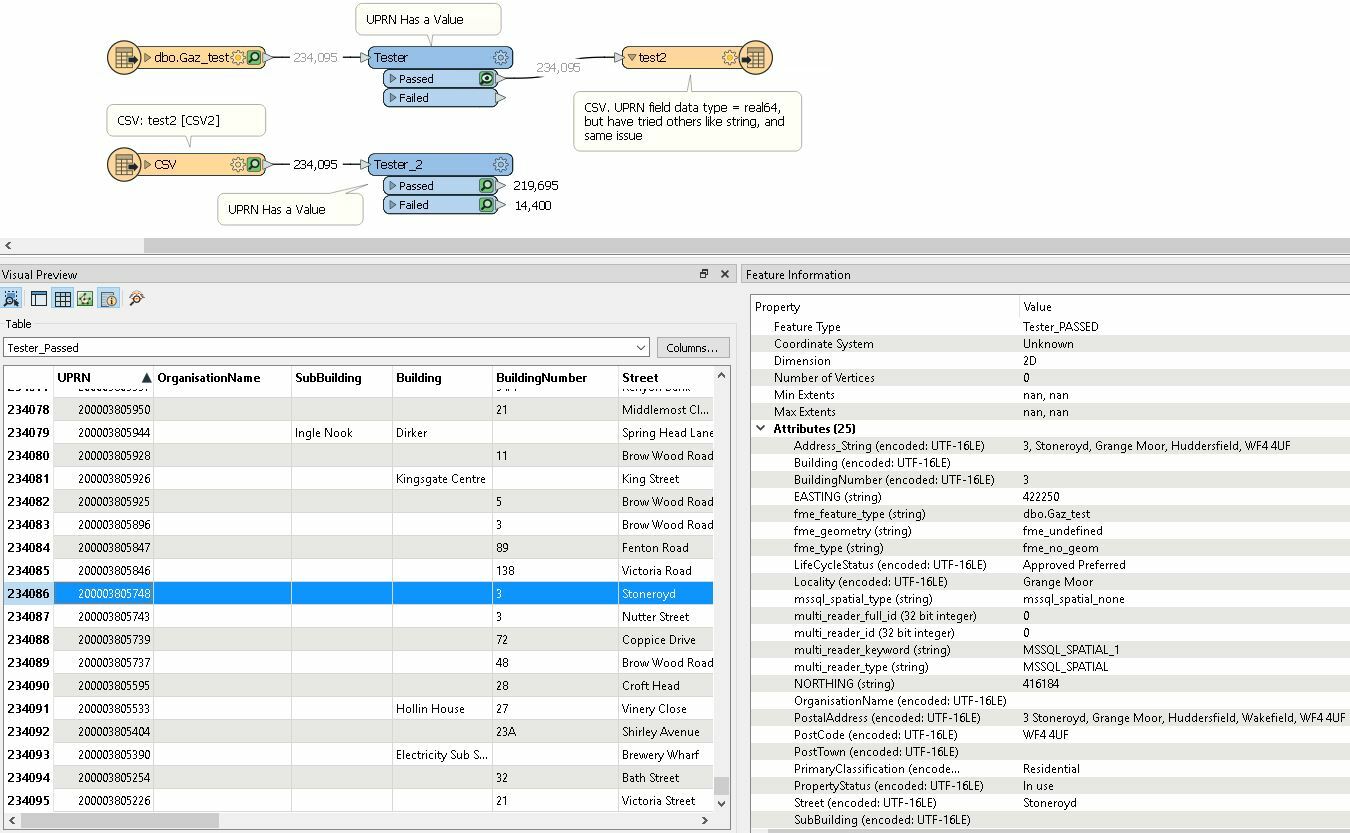
Second capture is the output after reading the CSV (lower workflow). Notice that there are 14400 records with null UPRN.