Hi everyone,
I have a series of regularly produced Excel files, each containing a number of sheets. The number and name of the sheets in each file isn't fixed.
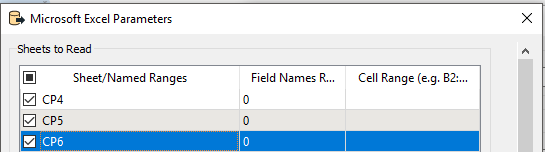
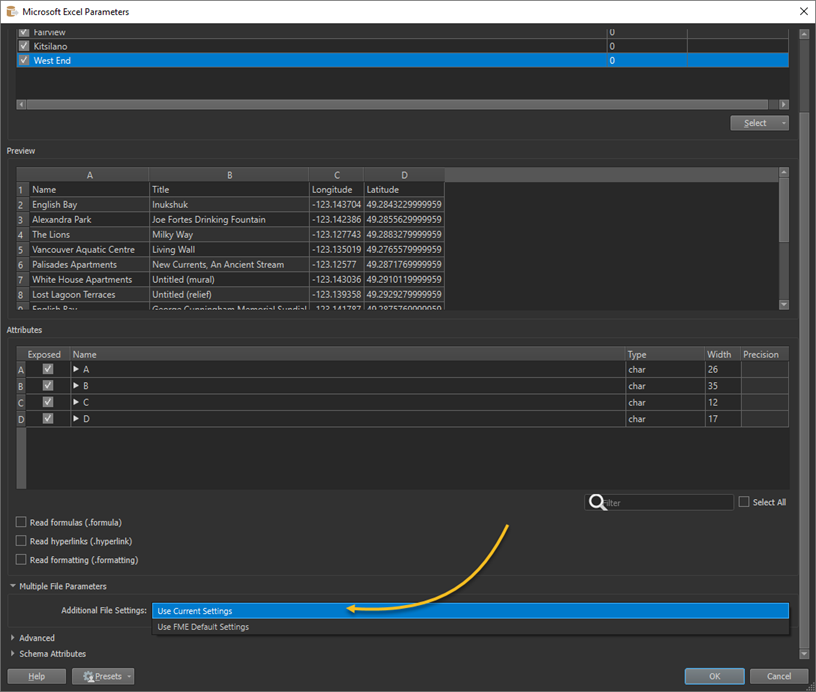
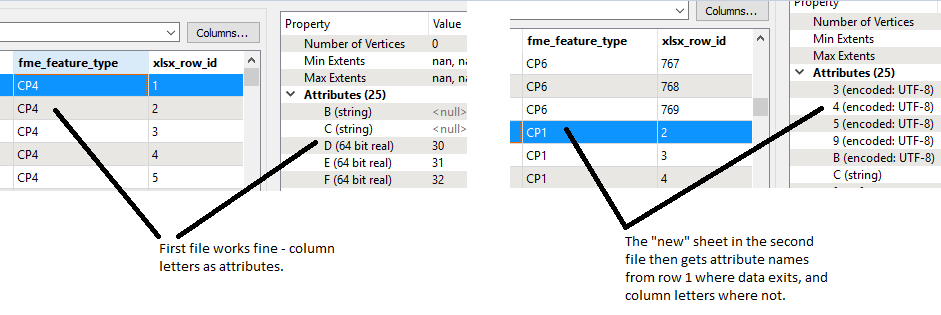
I can read data from all the sheets no problem by keeping the reader parameters blank - but annoyingly for these files the header starts on row 2 and in some cases junk is written into row 1. As such, FME picks up attribute names from row 1, so for one sheet the attribute for column B might end up named"995" and for the next sheet it might be "376", so I end up with a lot of attributes where there should be one - ideally just called "B".
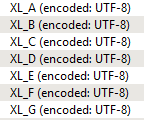
Is there any way to force the Excel reader to always use column letter as the attribute name regardless of how many sheets are in a file and what they are called?