I've got some confusing to clear, and hope to find an answer here.
I have 2, completely the same datasets, uploaded to ArcGIS Online. Now, i want to update them. To test it, i took 2 completely identical layers, read them from AGOL and now, it shows differences. Can someone explain me what the problem is?
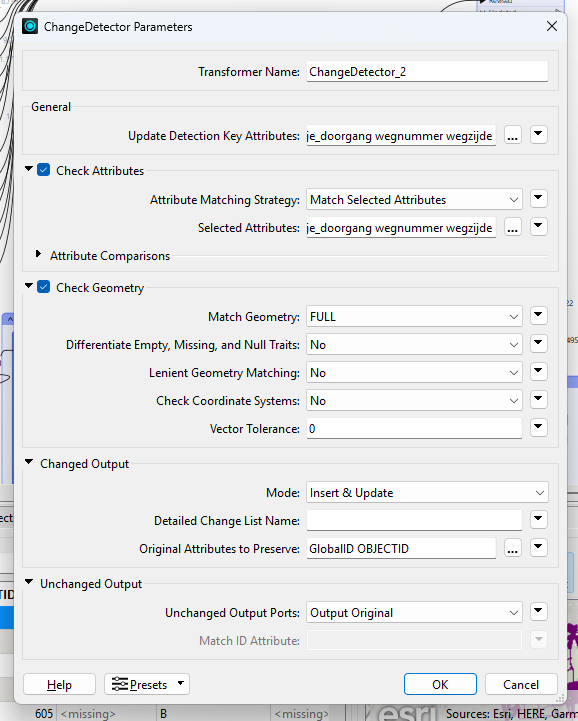
If i only check on attributes, then there is nothing wrong, but if i also check on geometry, there is somewhere a change, and the Changedetector gives updates as output, but it should be unchanged.
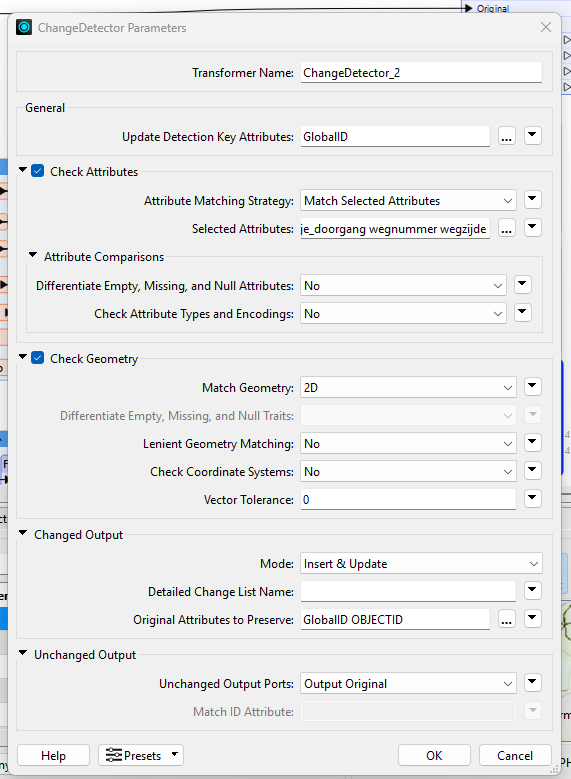
All the data is 2D, there is no 3D. In the update detection key attributes, i selected all the attributes, but left GlobalID and OBJECTID out of it. same for check attributes.
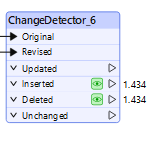
Even more confusing, if i do the same process in a new workbench, with the same sources etc, i get different results. Sometimes it igeve met 900 updated, and somethimes 1322
Thanks in advance!
Best answer by bwn
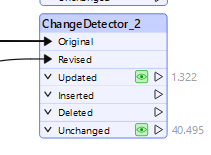
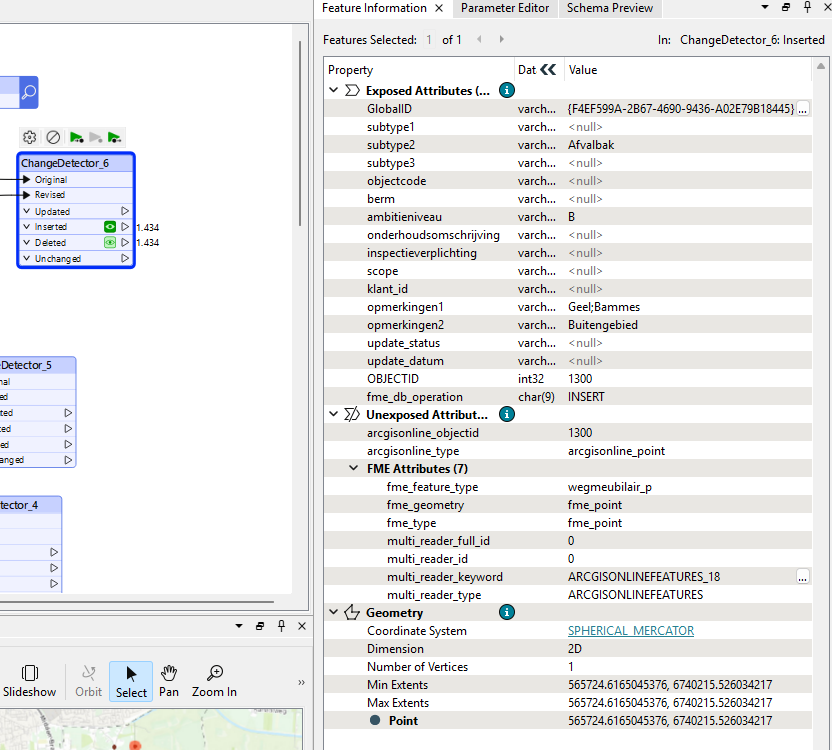
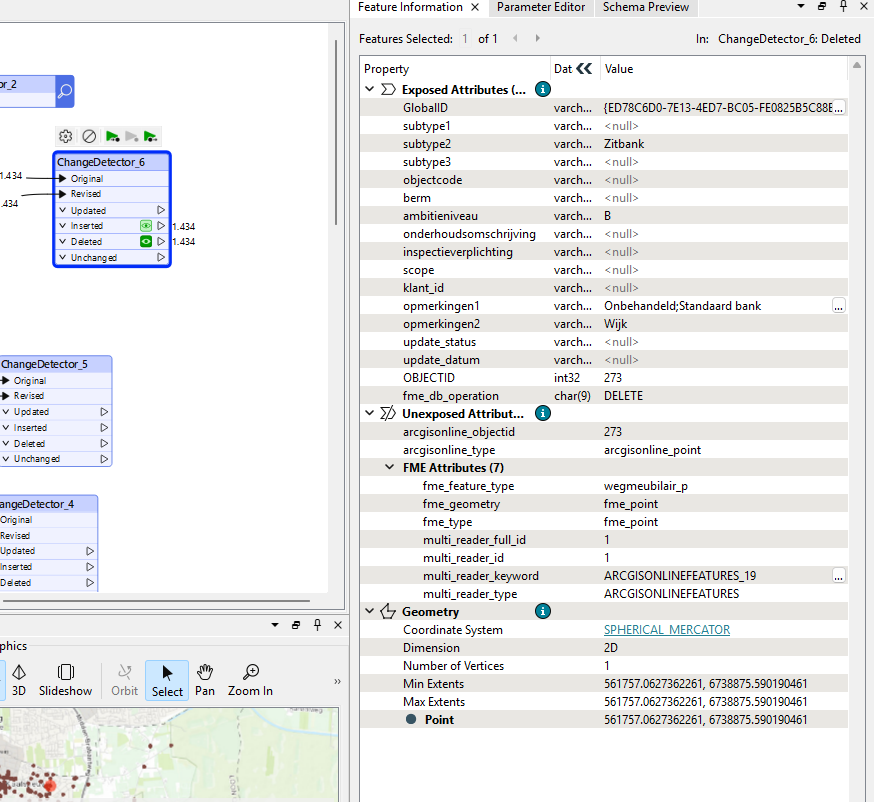
this is the ouput, but im not sure if i understand it. Why does it delete all of the original features and inserts all of the revised features?
revised feature:
Because a Global ID in a Geodatabase is a GUID. By design, a GUID is meant to be very, very probably an absolutely unique identifier that will not be in any other system used.
In your case, the Features in the comparison Feature Class had Global IDs that were independently generated from the original Feature Class. They are not then a common unique identifier value between the two feature classes, and is why GUIDs are not necessarily a good Unique ID unless careful to replicate it between replica datasets, but most systems by default will otherwise make it a random, unique value that is a value not found anywhere else in any of the systems.
ChangeDetector is saying that of 1,434 comparison features, there were zero features that had the same GUID as the Original features, so to send the updates to a Writer would need to Delete the 1,434 original features with their GUIDs that do not exist in the Revised features, and in place, insert the new 1,434 features with their different GUID values.
Looking at the screenshots of your sample data, there appears to be no common, unique identifier values between the feature classes, and so ChangeDetector cannot be used using the Feature Class attributes only.
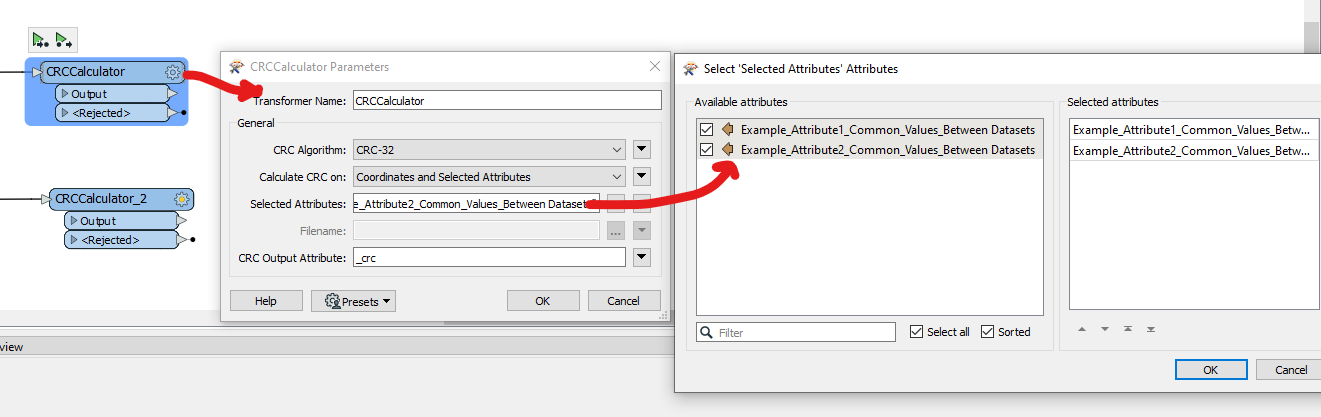
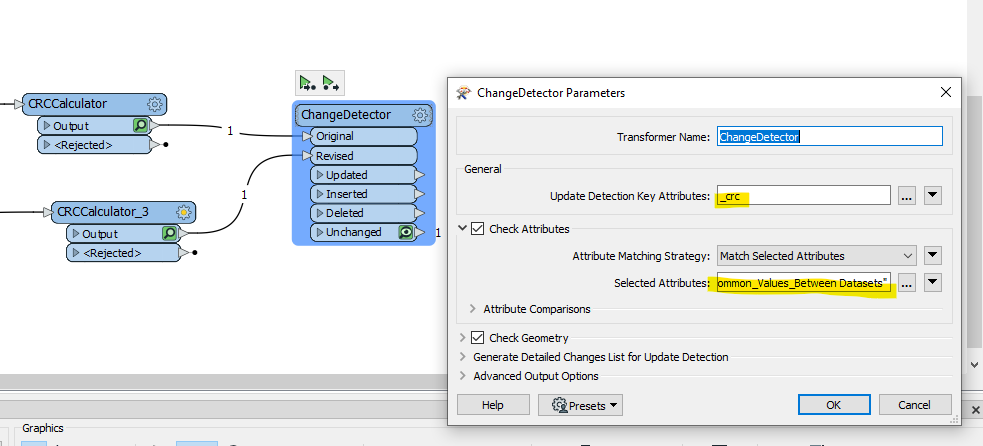
A close approximation would be to generate a Hash/Checksum as a pseudo-unique key value using CRCCalculator. The _crc Attribute output is not a random number, but a binary value calculated as a function of the Attribute values and Geometry and will be the same value for 2 Features that have the same Attribute values and the same Geometry.
This can instead be used with ChangeDetector like this:
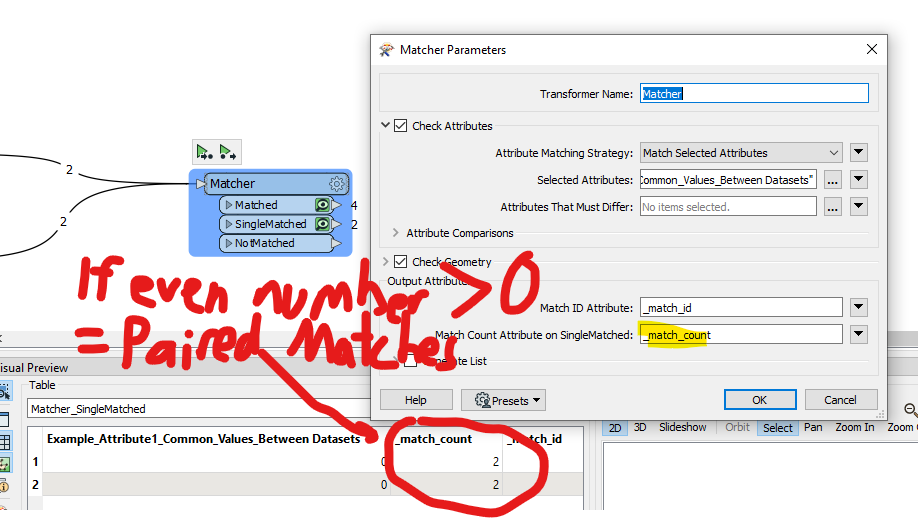
An alternative, less strict method is to use Matcher instead of ChangeDetector.
Matcher works like ChangeDetector but does not use a common Key Attribute to determine which features to compare. Instead it will output a count of how many matches exist. Logically, if Feature Class B was a replica of Feature Class A, then all Features would have a non-zero, even-numbered, _match_count. If there are any odd-numbered _mount_count, or features with no matches, then Feature Class B would be different from Feature Class A.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Hard to say without data :) but in general, if the inputs in the ChangeDetector are not exactly the same format, the same geometry can be stored in a different way and therefore can be found as Changed.
What I usually do:
Isolate the same feature in both Original & Revised.
Connect one inspector to Original & Revised and force it to open in the Data Inspector, not the Visual Preview.
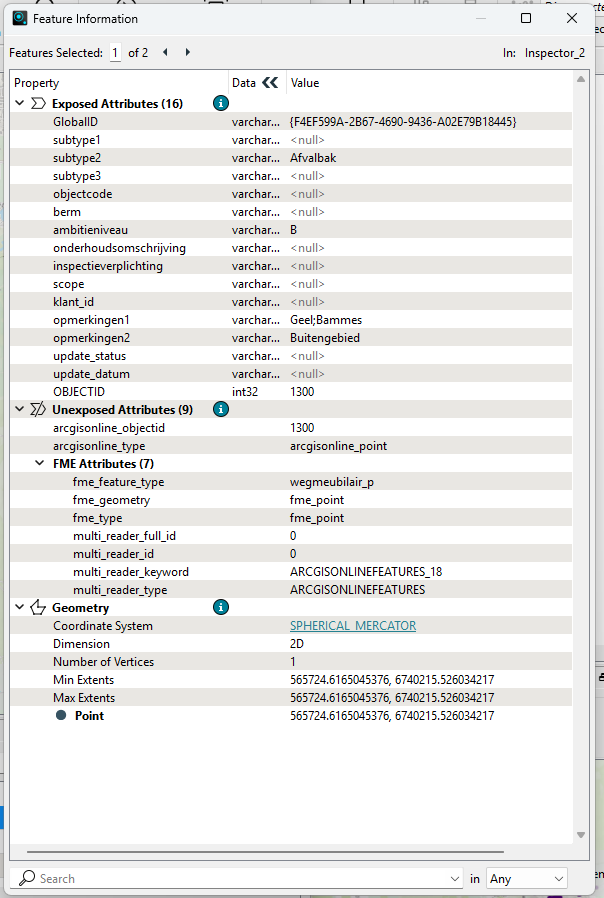
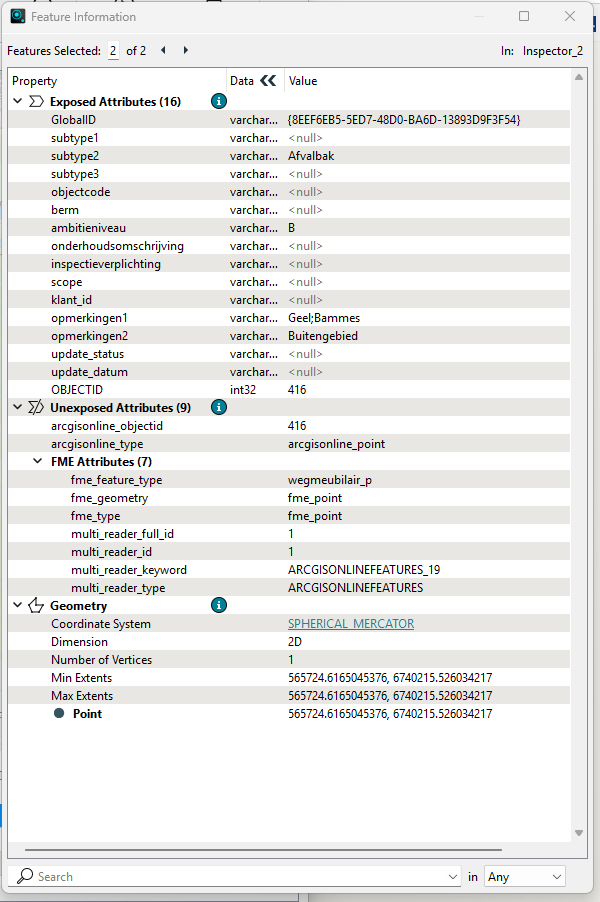
Select one of the 2 features and look at the geometry in the Feature Information window on the right side.
Select the other feature and check if and how the geometry differs from the other.
Also, if I compare and have 2D geometry, I use 2D. I almost never have used FULL.
Also: this being ArcGis data, the coordinates tend to have a humongous amount of decimals, far more than is necessary. And with Lenient Geometry Matching set to No, and Vector Tolerance set to 0, a difference of 0.0000001 meter will already cause this. And that might simply be a rounding error, or even a floating point error. So I’d give a reasonable tolerance, and not set it to 0. Seeing as you have Dutch-sounding names for your attributes, I’m going to assume your coordinate system is EPSG:28992. In which case I’d start with setting a tolerance of 0.001 (ie one millimeter), and see what that does.
Hi all, thanks for your input! @nielsgerrits i have done what you suggested, and they look completely the same to me, or it could be that im missing something, am i?
I have also re run the workbench on 2D, and with or without lenient geometry, but that didnt make a difference. @ebygomm @s.jager I have also tried the tolerance, set in multiple ways, from 0.1 tot 0.0000001. That also didnt make any difference, however, it did make a difference when i was comparing some polygons.
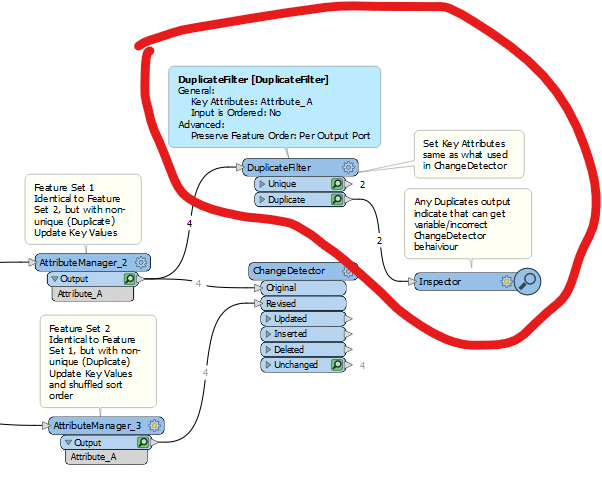
I suspect the reason for this is that there are duplicate Features with the same “Update Key Attribute” values.
The setup shown for ChangeDetector in the first post is not how the Transformer is meant to be configured. ChangeDetector for most use cases needs an Update Key Attribute(s) which is a unique identifier.
If they are not unique: ChangeDetector will operate in what seems like “random” ways in which it detects what has changed or not.
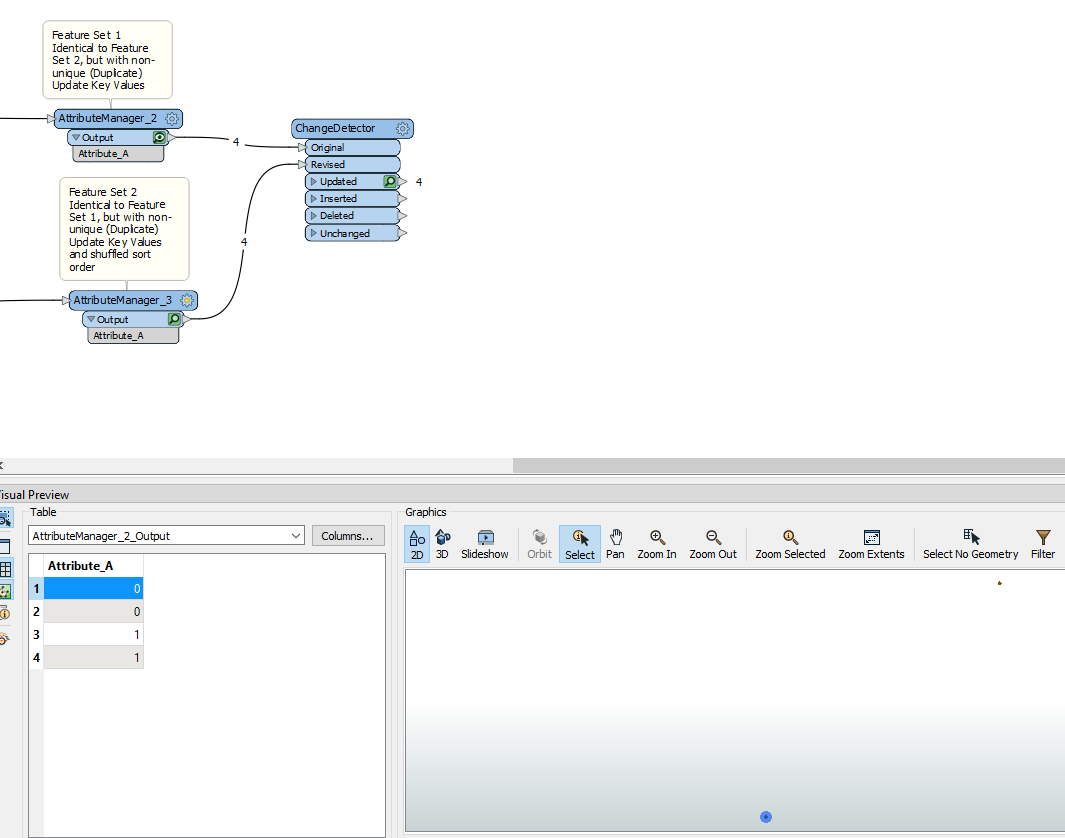
For example, here are two exactly identical Feature sets of Points, but they do not have a Key Attribute that is unique, and the features with duplicate Key Attributes have different Point Geometries Eg. Where Attribute_A = 0, corresponds to two different features being a Point at 0,0 and a Point at 1,1.
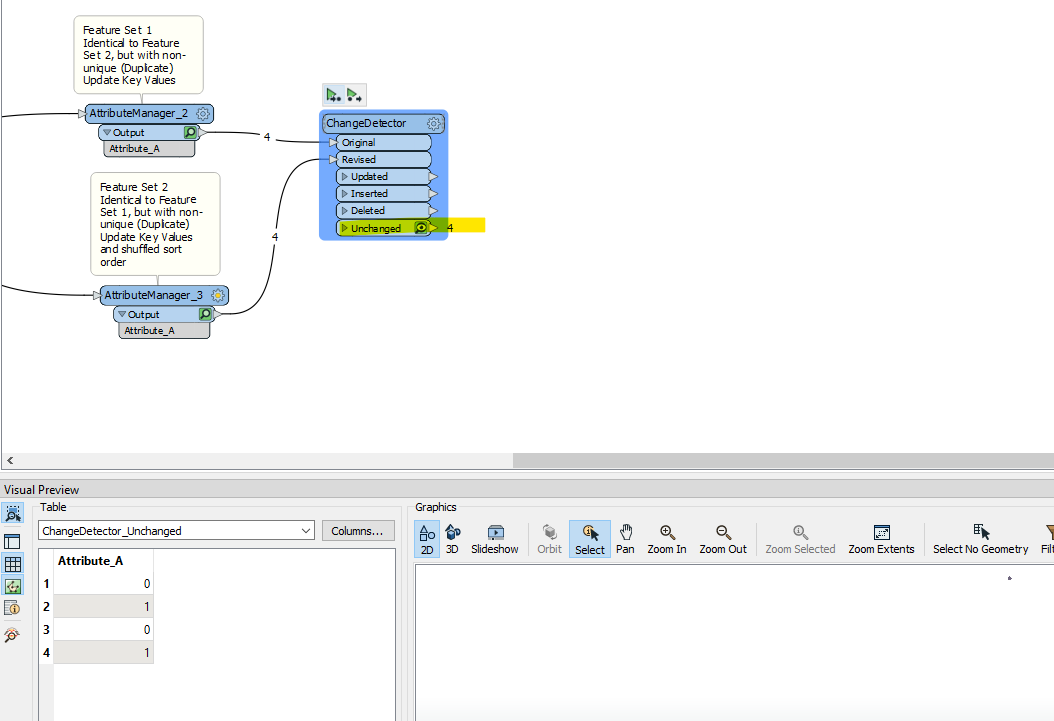
When the sort order is shuffled for Feature Set 2, then despite being the same Features, they will output on the “Updated” port, because ChangeDetector only compares against the first match to determine if the Original has changed or not. It found and compared against a Point that had the same Unique Key Attribute value, but because was in a different sort order, had a different point coordinate.
On the other hand, if the Sort Order is kept the same, then they will instead output on the “Unchanged” Port, because the first feature found to compare has the same unique key value and coincidentally has the same Point geomety.
So, this is why the “golden rule” for ChangeDetector is: Always use unique (non-duplicate) Key Attribute combinations in the “Update Detection Key” parameter for ChangeDetector.
From the first post, by instead using the Attribute values themselves as the Key Attributes, then this looks like this would be prone to encountering other Features that have duplicate Attribute values and have a different geometry.
As an aside, it is also pointless to use any Attributes in “Check Attributes” used in the Key Attributes Parameter. The Key Attribute Parameter(s) is what is used to find matching Features between the Orginal and Revised Features and therefore the values will always match and “Check Attributes” on the same Attributes will not be different.
To check if there are Features with duplicate Key Attribute values, then an easy way is to inspect using DuplicateFilter
You will need an ID which is the same in both datasets. GlobalId is a generated guid and should be pretty unique every time. So the ChangeDetector now reports that all features are deleted and newly created, based on GlobalId, which is expected.
this is the ouput, but im not sure if i understand it. Why does it delete all of the original features and inserts all of the revised features?
revised feature:
Because a Global ID in a Geodatabase is a GUID. By design, a GUID is meant to be very, very probably an absolutely unique identifier that will not be in any other system used.
In your case, the Features in the comparison Feature Class had Global IDs that were independently generated from the original Feature Class. They are not then a common unique identifier value between the two feature classes, and is why GUIDs are not necessarily a good Unique ID unless careful to replicate it between replica datasets, but most systems by default will otherwise make it a random, unique value that is a value not found anywhere else in any of the systems.
ChangeDetector is saying that of 1,434 comparison features, there were zero features that had the same GUID as the Original features, so to send the updates to a Writer would need to Delete the 1,434 original features with their GUIDs that do not exist in the Revised features, and in place, insert the new 1,434 features with their different GUID values.
Looking at the screenshots of your sample data, there appears to be no common, unique identifier values between the feature classes, and so ChangeDetector cannot be used using the Feature Class attributes only.
A close approximation would be to generate a Hash/Checksum as a pseudo-unique key value using CRCCalculator. The _crc Attribute output is not a random number, but a binary value calculated as a function of the Attribute values and Geometry and will be the same value for 2 Features that have the same Attribute values and the same Geometry.
This can instead be used with ChangeDetector like this:
An alternative, less strict method is to use Matcher instead of ChangeDetector.
Matcher works like ChangeDetector but does not use a common Key Attribute to determine which features to compare. Instead it will output a count of how many matches exist. Logically, if Feature Class B was a replica of Feature Class A, then all Features would have a non-zero, even-numbered, _match_count. If there are any odd-numbered _mount_count, or features with no matches, then Feature Class B would be different from Feature Class A.
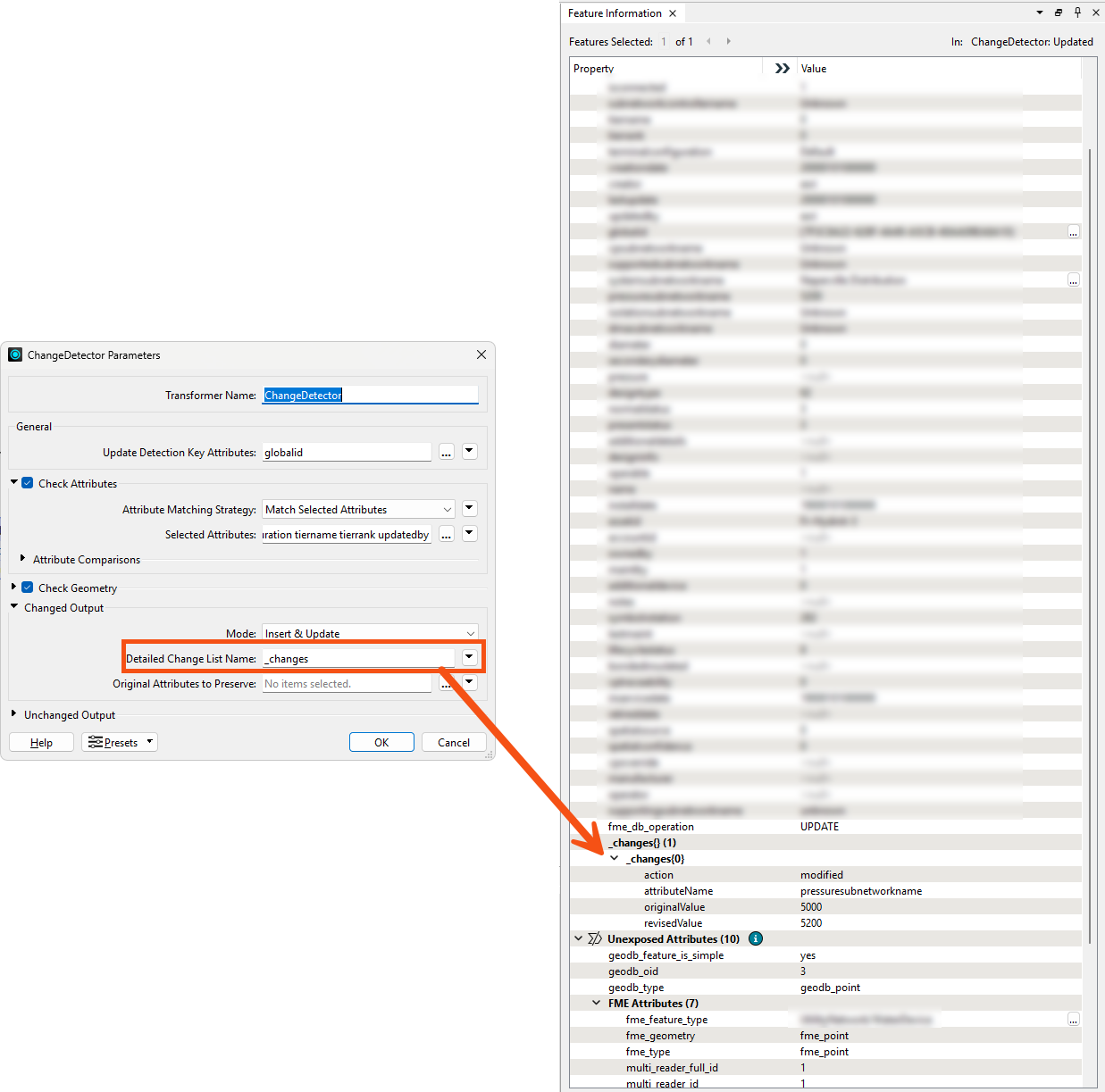
The precision of geometry data can also be flagged by the ChangeDetector transformer. I recommend setting the Vector Tolerance to 0.001 to ensure features are not incorrectly labeled as "Updated."
Additionally, if you want to view the specific values that have been changed that were identified by the ChangeDetector, you can configure the Detailed Change List Name by assigning a name to it. For example, I set the name as "_changes." This allows you to see all the modified values in the Feature Information window, as identified by the ChangeDetector. I hope this provides insight into why your identical features may have been flagged as "Updated."