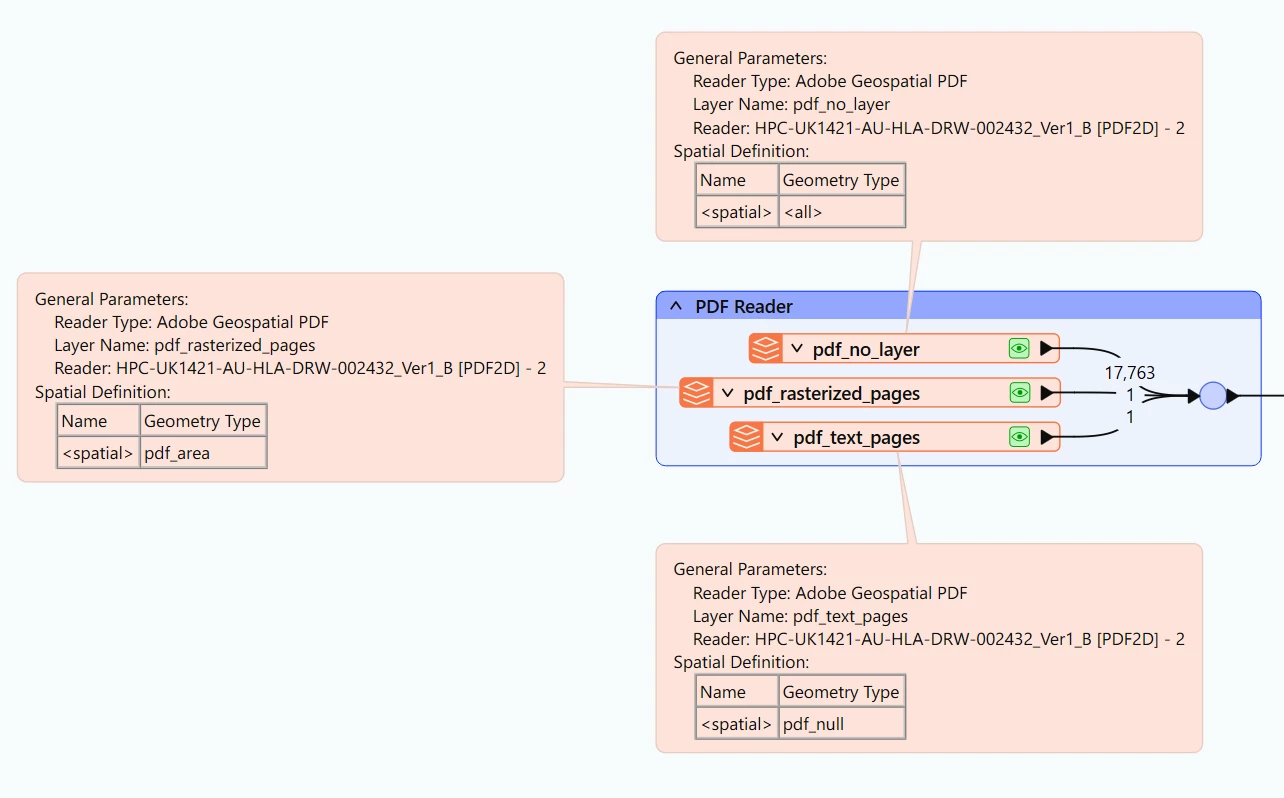
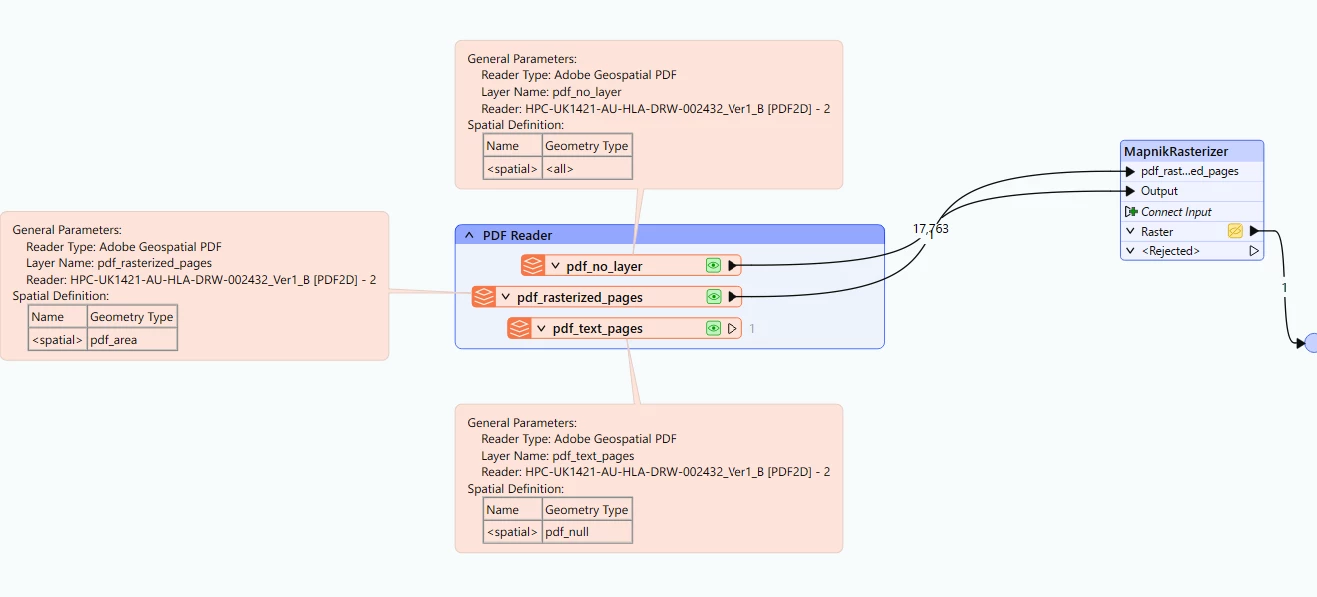
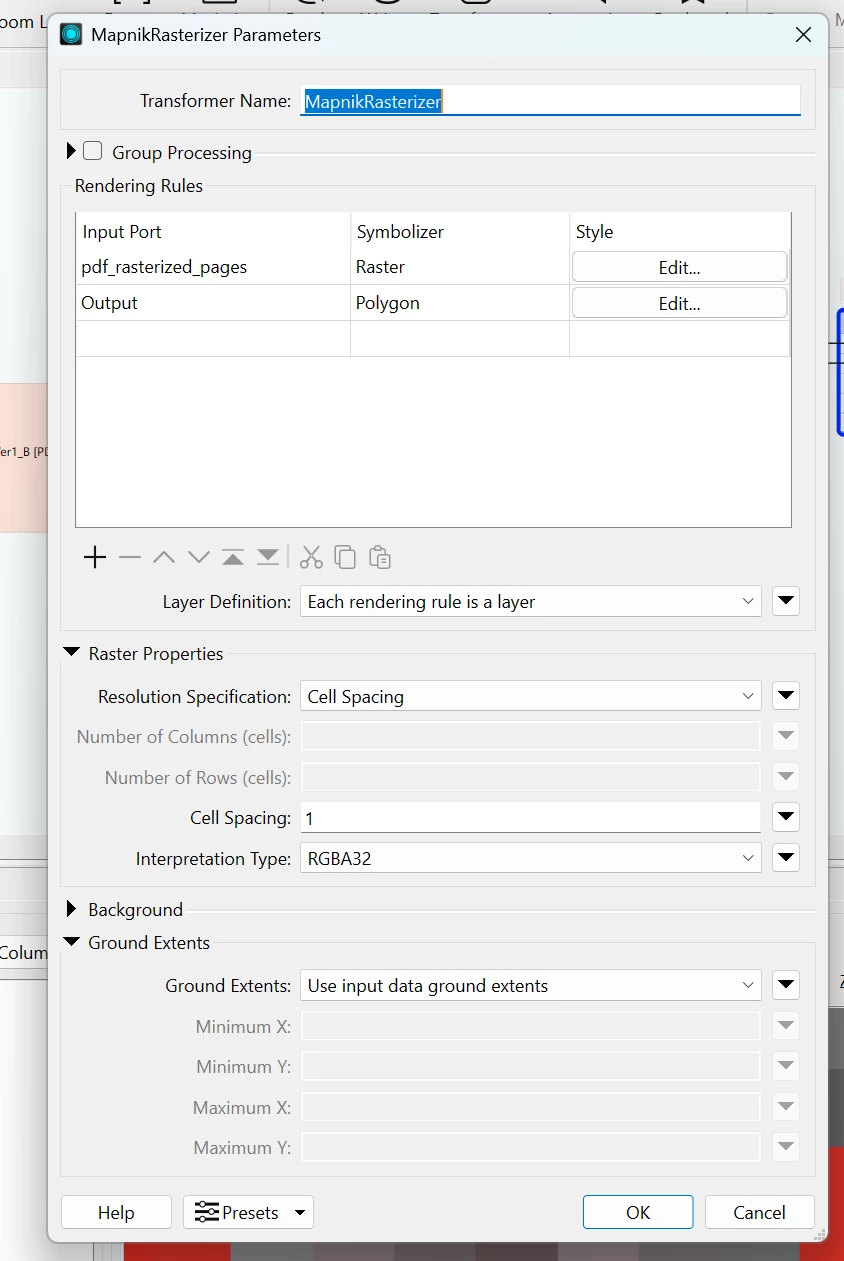
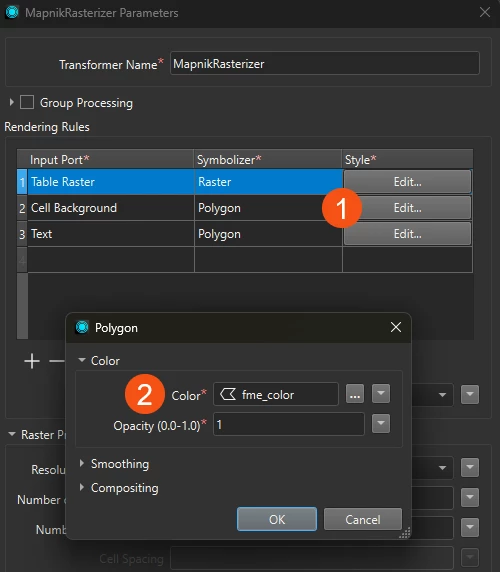
I would like to read what i am seeing below :

In the above image under the RED text / numbers is BLACK text /numbers (i do not want the PDF READER to read this but rest in BLACK visible in above is okie)
e.g. When i read PDF it reads T64 but i want to read T100 + other text/numbers visible in above image OR I want to read U 22700 mm and NOT U 22000 mm OR I want to read U 22950 mm and NOT U 22200 mm
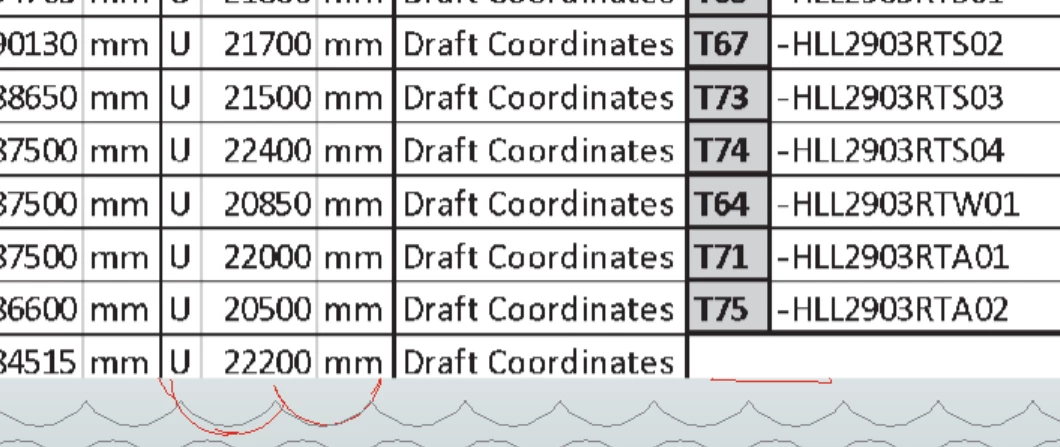
This is how my PDF READER