I'm a beginner with FME and have only used it for a couple of weeks doing simple tasks in Workbench so my knowledge is not very good. I'm now trying to set up an automatic process for downloading data(zip files) from a Swedish authoritys website:
http://extra.lansstyrelsen.se/gis/Sv/lansvisa-geodata/sodermanlands-lan/Pages/default.aspx
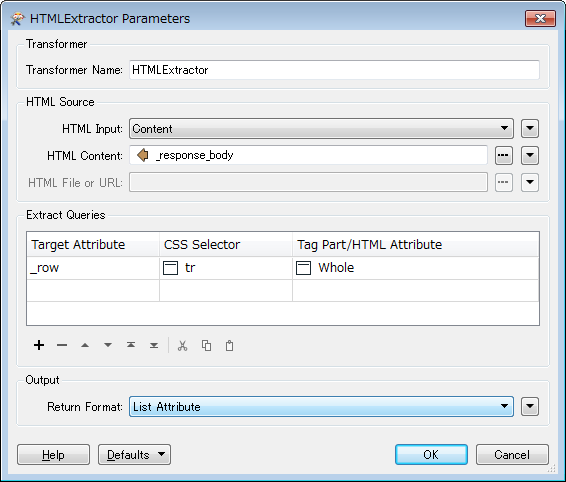
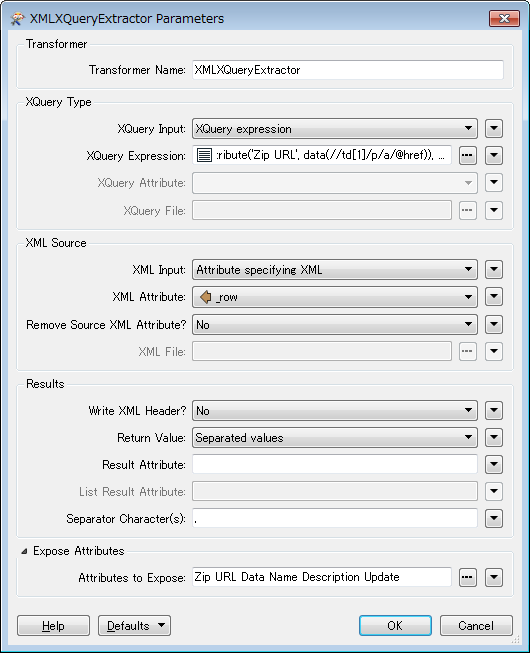
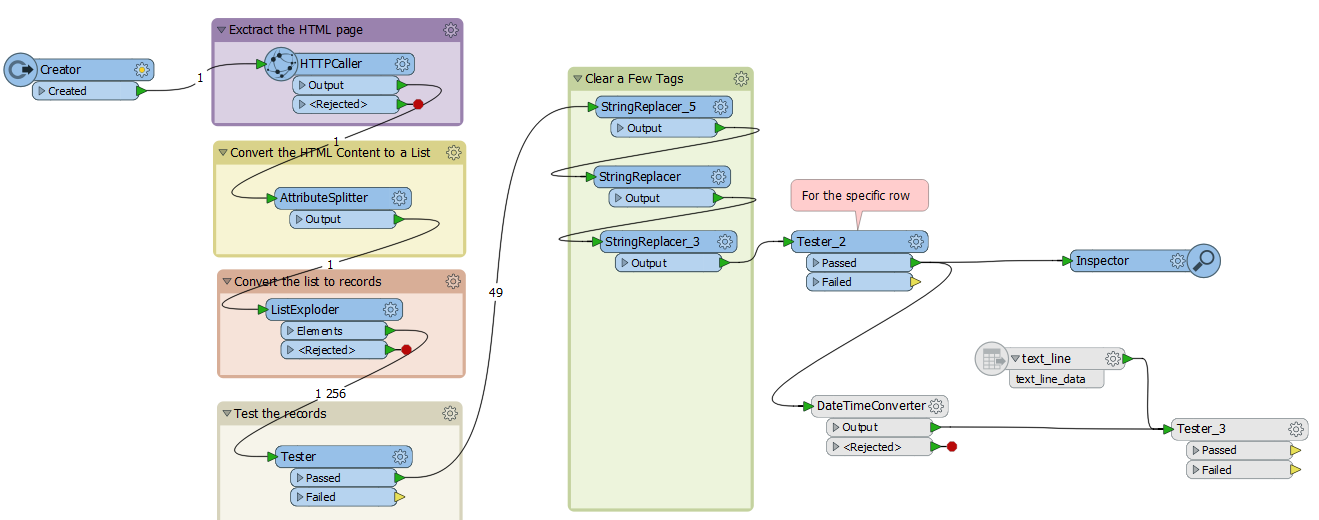
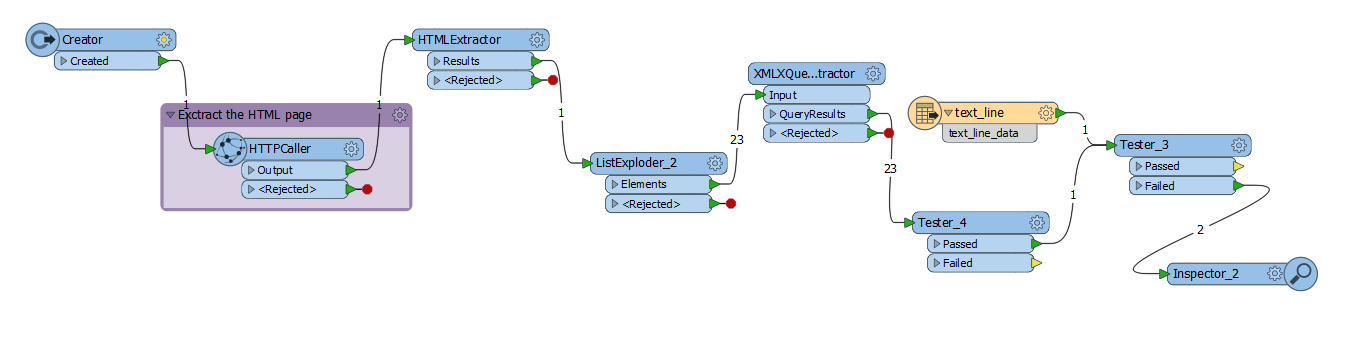
I have created a FME script for downloading the specific zip (LstD Ädellövinventering) using a HTTPCaller. I only want the script to run when the specific zip file has been updated. Is that possible? And how does that work? I also want to be notified by email if the data failed to download. And maybe let the script run til the download is sucessful if that's a good idea?