I’ve got a bunch of points (1 to maybe 40+) that are changing regularly (live data), and I want to find out which polygons those points are intersecting.
They are big polygons with lots of vertices.
What is the most efficient and/or fastest way to do that?
Should I:
Have a SQL Spatial Reader and read all those polygons and use a PointOnArea Overlayer transformer.
Use a FeatureReader with a Spatial Filter Initiator OGC Intersection and use a PointOnArea Overlayer.
Should I use a SQLExecutor and rely on the database?
I’ve tried the first two and I’m not sure which is best.
Thanks
Best answer by bwn
Hi Peter,
Have not specified what the underlying database but for live data it can often be cheapest and easiest to just use SQLExecutor with say: STIntersects() or whatever equivalent for the underlying spatial DB since with spatial indexing enabled on these usually it can be pretty quick. Otherwise the next cheapest Transformer is read the features in and use SpatialFilter or even NeighborFinder I find has a little versatility to catch those edge cases where if it doesn’t intersect, then at least get the nearest polygon.
Coincidentally I do deal somewhat in my professional life in fire/QFD related analyses/overlays, so feel free to reach out by PM if want to share the specific use case.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Have not specified what the underlying database but for live data it can often be cheapest and easiest to just use SQLExecutor with say: STIntersects() or whatever equivalent for the underlying spatial DB since with spatial indexing enabled on these usually it can be pretty quick. Otherwise the next cheapest Transformer is read the features in and use SpatialFilter or even NeighborFinder I find has a little versatility to catch those edge cases where if it doesn’t intersect, then at least get the nearest polygon.
Coincidentally I do deal somewhat in my professional life in fire/QFD related analyses/overlays, so feel free to reach out by PM if want to share the specific use case.
I agree with @bwn, use the database as much as possible if you already have a spatial index there.
Additionally, if your polygons are really detailed, you could consider a two-stage approach where you first generate (oriented?) bounding boxes of your polygons and check first if the point is within the bounding box. That should be lightening fast, and you can then send only those within to be compared with the detailed polygon.
you could consider a two-stage approach where you first generate (oriented?) bounding boxes of your polygons and check first if the point is within the bounding box
If the database is Oracle, then Oracle does that automatically for you when using the spatial index, so in that case there’s no need to do that yourself, on the contrary: that would only slow it down. SQL Server uses a slightly different approach, but even there I wouldn’t use this two-step approach in the database. I’d only use this approach if the only viable solution is to do all the work in FME, because in that case you’re right: it would save a lot of unnecessary calculations.
if you already have a spatial index there
If it isn’t there, create it. It’ll make spatial queries a lot faster.
On the whole, I agree with David and bwn: Let the database do the work. Databases are designed and optimized to handle sometimes incredibly large datasets (if we’re talking Oracle, SQL Server, PostGIS, etc), so I always try to offload as much as I can to the database instead of letting FME do things.
The drawback of that I find is that my workspaces are not as self-documenting as I’d like them to be, but with a few extra annotations that can easily be rectified - and does not justify the loss of performance.
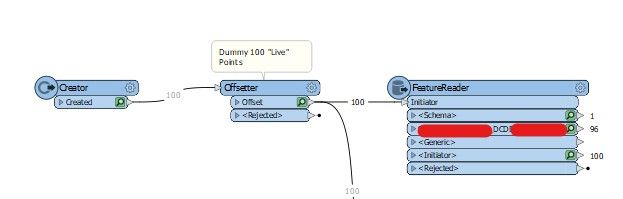
Proof-of-concept if the “Live” Points are coming from a data source outside the Area-of-Intersection Spatial DB. ie. Want to use the Spatial Index but the Point Table doesn’t live inside the Spatial DB Server Instance.
Doing this with SQL Server, but concept would be the similar for any Spatial DB. I actually trialled two ways, one with FeatureReader and one with SQLExecutor
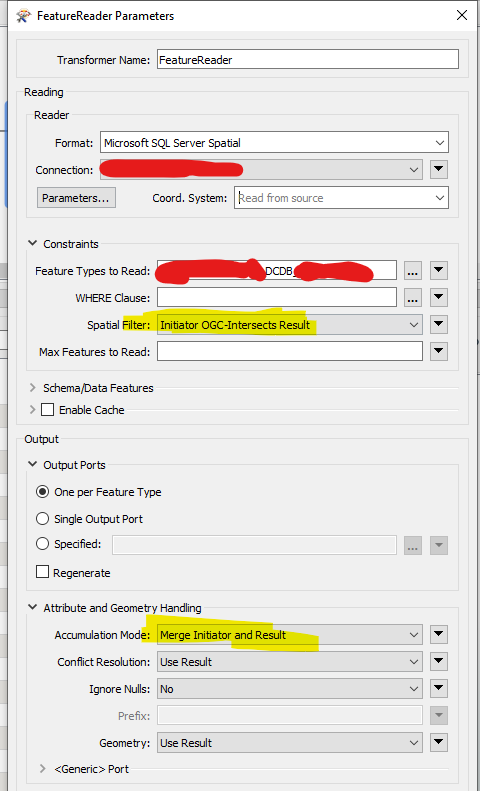
I wasn’t 100% sure if FeatureReader would through its SQL Server API in the background use STIntersects() when the user sets the Spatial Filter parameter, but it looks like it does, making this fairly fast since STIntersects() in SQL Server triggers Spatial Index lookup.
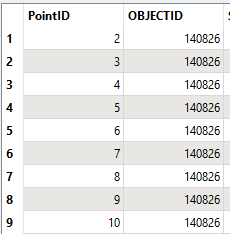
So basically looks like this with 100 simulated “Live” Points that get sent to SQL Server via a FeatureReader to find from a 1,000,000 Cadastral Parcel database which ones they intersected with (looks like 4 of them were in between parcels in a roadway so didn’t return a result)
The FeatureReader uses the Initiator Points that in the background are testing STIntersects() SQL, and returns the results in <1 second against searching ~1,000,000 Cadastral Parcels.
Note Parameter setting to merge the Initiator Attributes with the Result Attributes to do the “JOIN”
Output of the FeatureReader gives the PointID Attribute of the Initiator Point Geometry merged with the OBJECTID of the Parcel(s) it intersected with in SQL Server.
The SQLExecutor method quite a bit harder in inserting the points into a DECLARE’d Table Variable and doing an SQLExecutor SELECT … FROM … WHERE MyPolygon.SHAPE.STIntersects(@My_Point_Tabke.SHAPE) = 1 . It works and is a little more efficient in doing it in one SQL Statement rather than the 100 separate FeatureReader SQL SELECTs above, but will only post that longer solution if the FeatureReader solution doesn’t work...
The SQLExecutor method quite a bit harder in inserting the points into a DECLARE’d Table Variable and doing an SQLExecutor SELECT … FROM … WHERE MyPolygon.SHAPE.STIntersects(@My_Point_Tabke.SHAPE) = 1 . It works and is a little more efficient in doing it in one SQL Statement rather than the 100 separate FeatureReader SQL SELECTs above, but will only post that longer solution if the FeatureReader solution doesn’t work…
Those are some great findings, and they corroborate my own experience.
Concerning the SQLExecutor, my experience is good if the number of input features is reasonable, and/or the SQL is very simple.
However, as statement complexity and number of input features goes up, performance goes down quite a lot. I suspect this has to do with the SQLExecutor not supporting bind variables, forcing the backend to evaluate the entire SQL statement for each feature. All this just to say that I think the FeatureReader would be my preferred solution here.
you could consider a two-stage approach where you first generate (oriented?) bounding boxes of your polygons and check first if the point is within the bounding box
If the database is Oracle, then Oracle does that automatically for you when using the spatial index, so in that case there’s no need to do that yourself, on the contrary: that would only slow it down. SQL Server uses a slightly different approach, but even there I wouldn’t use this two-step approach in the database. I’d only use this approach if the only viable solution is to do all the work in FME, because in that case you’re right: it would save a lot of unnecessary calculations.
Thank you all for your answers. The polygon database is a MSSQL DB. SDE.
If the points were from a second database (also MS SQL not SDE), not the source of the polygons, that would probably negate some of the advantages of a sql spatial query.
It’s also a little academic at the moment since both databases are being upgraded and the environments changing. Maybe it will make more sense with new MS SQL versions + hardware.
It seemed pretty wasteful to read in whole state regions (x3) every time an update was happening.
Thank you all for your answers. The polygon database is a MSSQL DB. SDE.
Hi Peter,
For this type of query I would generally recommend instead using the SQL Server Spatial Reader and not use SDE. The SDE interface in this application can be waaaaay slower. In my brief test for the Intersecting Polygons by instead testing with the SDE Reader looks like it may be doing this through arcpy.analysis.Intersect() which is putting an extra interface layer / extra overhead across the SQL Server backend, and this was easily 100 times slower for the 100 test points I directed to it (again though this is use case for Point data coming from outside the Polygon DB……..otherwise SQLExecutor can be used to directly write SQL statement for SELECT … FROM Points , Polygons WHERE Polygons.SHAPE.STIntersects(Points.SHAPE) = 1 )
Using the SQL Server reader within FeatureReader instead triggers directly in the backend STIntersects() ….which is generally the fastest lookup of the backend spatial index.
If the polygon is a versioned layer, then use the Versioned View in SQL Server read/writes which is typically FeatureClassName_vw or FeatureClassName_evw
If the points were from a second database (also MS SQL not SDE), not the source of the polygons, that would probably negate some of the advantages of a sql spatial query.
Not necessarily. There are ways of letting databases contact each other directly, so that could be an option.
I don’t know much about your situation, but I can imagine this being a real-time situation. In that case you need to start thinking in moving parts:
Which parts of the problem are the heaviest to move? Bring the other parts to them, instead of the other way around.
Which mover is most efficient? The database (table to table for example), FME (webservice to table possibly), or maybe something else even?
In the case of the large databases, the biggest drain on performance is almost always the read from disk. So in order to improve performance, you want to either avoid that or minimize it as much as possible (Hence Oracle’s trick with spatial indices: every spatial index has an root element which is the MBR of all elements in that index, and that goes for partitioned indexes as well - so using the MBR Oracle can be lightning fast in eliminating time-consuming vertex-calculations. SQL Server’s index approach follows a slightly different, but similar approach: eliminate as much as possible beforehand).
So if you can eliminate moving parts from taking part in the actual performance beforehand (possibly by where-clauses based on attributes or something - which should be indexed as well!), that will also help with the performance.
And generally always remember that the big databases are specialized in handling very large datasets, and when talking very large I’m talking 100’s of millions of rows (10 million is, where I used to come from, not a big deal 😄).
It seemed pretty wasteful to read in whole state regions (x3) every time an update was happening.
Agreed. It would be wasteful and not necessary. It should be only once, and ideally only those regions affected. How to best achieve that, I can’t say without knowing a lot more about your environment and data (and even then there can be unforeseen obstacles, such as everyone in the office opening Outlook, or doing performance tests on a virtual server that shared its hardware with 2 other virtual servers - so after 1700 hours when the 2 others were idling, performance suddenly went bananas… don’t laugh, I’ve seen it all IRL...)