Example:
Feature 1
List{0} = 11
List{1} = 22
List{3} = 33
Feature 2
List{0} = 44
List{1} = 55
....more features
Should produce this csv-file:
11, 22
11, 33
22, 11
22, 33
33, 11
33, 22
44, 55 Remark: This is feature 2
55, 44
....
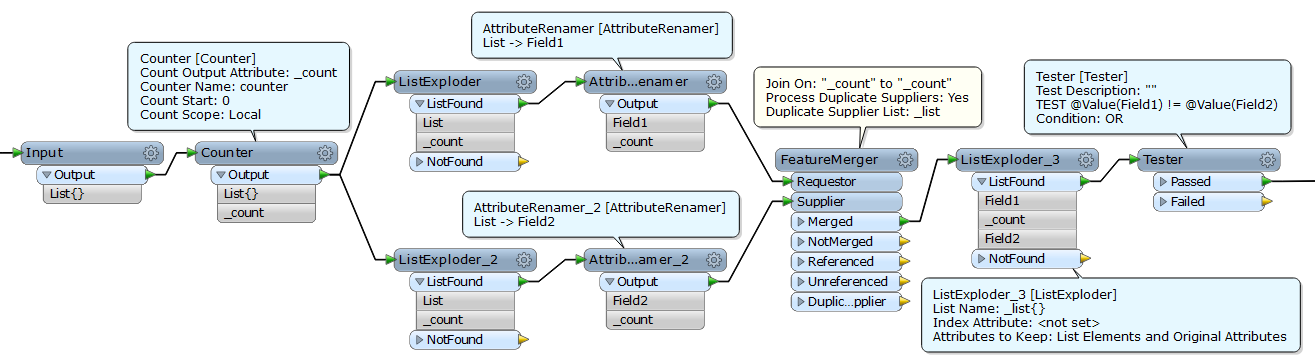
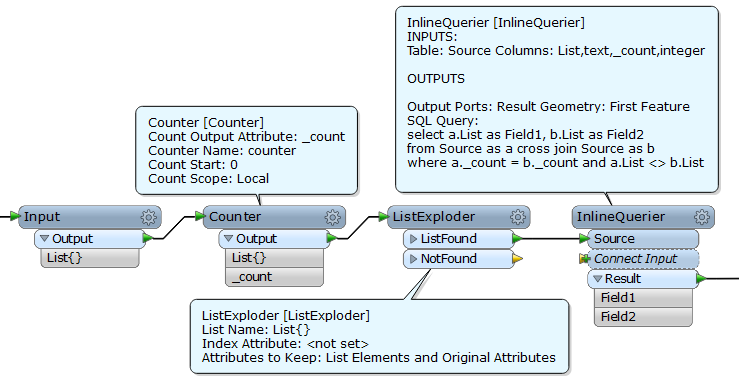
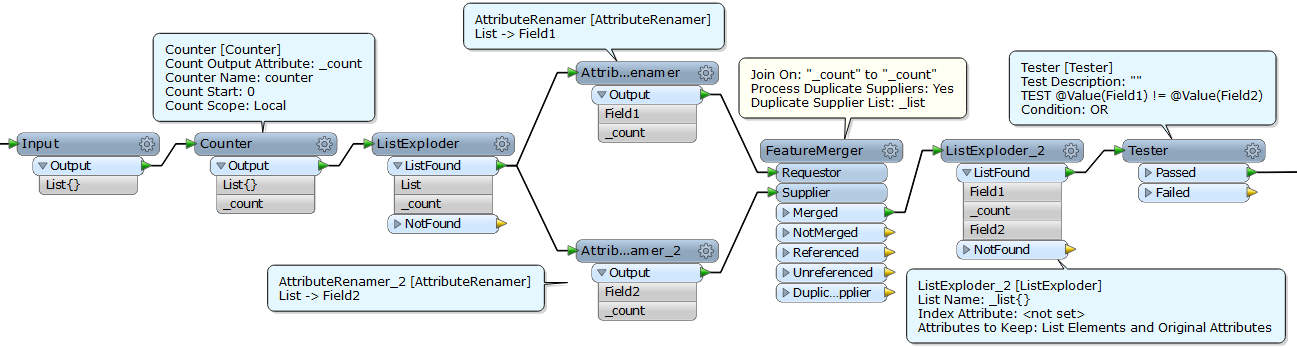
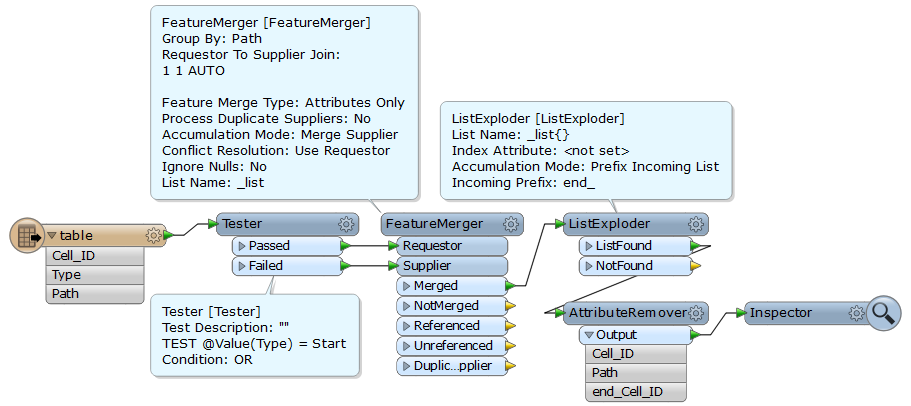
The lists seem to be fine, I can use AttributeExposer and output single items. So my challenge is to output the combinations while not knowing before rruntime how many list members there are (will most often be 2, and generally less than 4).
I have been experimenting with listExploder to give me one line per list member, but it leaves me with the combination problem. I'm new to FME, so a suggestion of appropriate transformers would be appreciated. Thank,s.
Regards Erik