Hi,
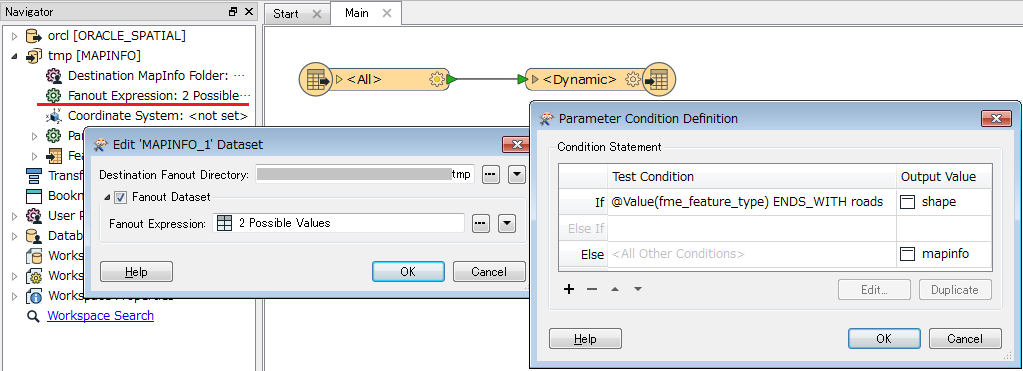
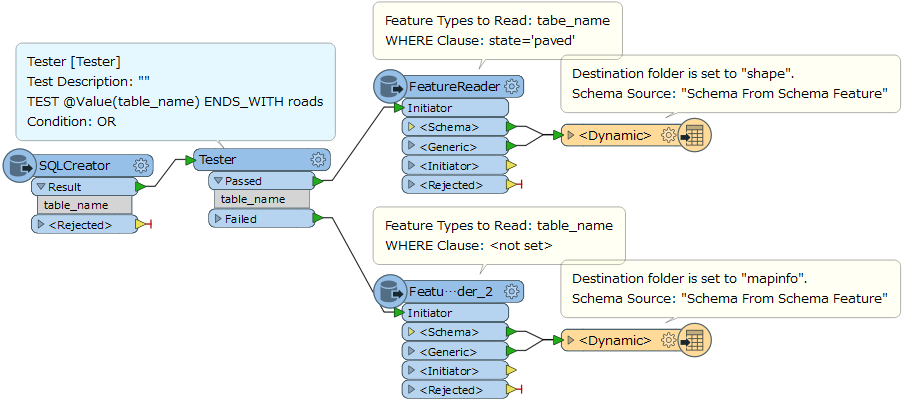
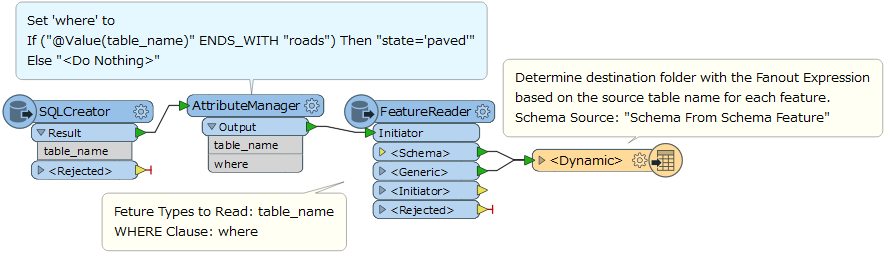
I would like to create an output folder based on the input file.
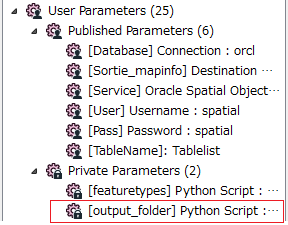
I created a user variable <output_folder> and I'm trying to determine the value using a python script.
Below is the error that I'm getting using this workspace
INCLUDE -- failed to evaluate Python script `def ParamFunc():
import fmeobject
def output_folder(feature):
feature = FME_MacroValues['featuretypes']
string='C:\Users\Administrateur\Documents\oracle_spatial\tmp'
if feature[10:]=='roads'
output_folder=string+'\shape'
else
output_folder=string+'\mapinfo'
return str(output_folder)
value = ParamFunc()
macroName = 'output_folder'
if value == None:
return { macroName : '' }
else:
return { macroName : str(value) }
'
Program Terminating
Translation FAILED.
File "<string>", line 5
feature = FME_MacroValues['featuretypes']
^
IndentationError: expected an indented block
Thanks