Hi,
I'm sorry if there's already a discussion about that, but I havn't found it.
Here's my problem :
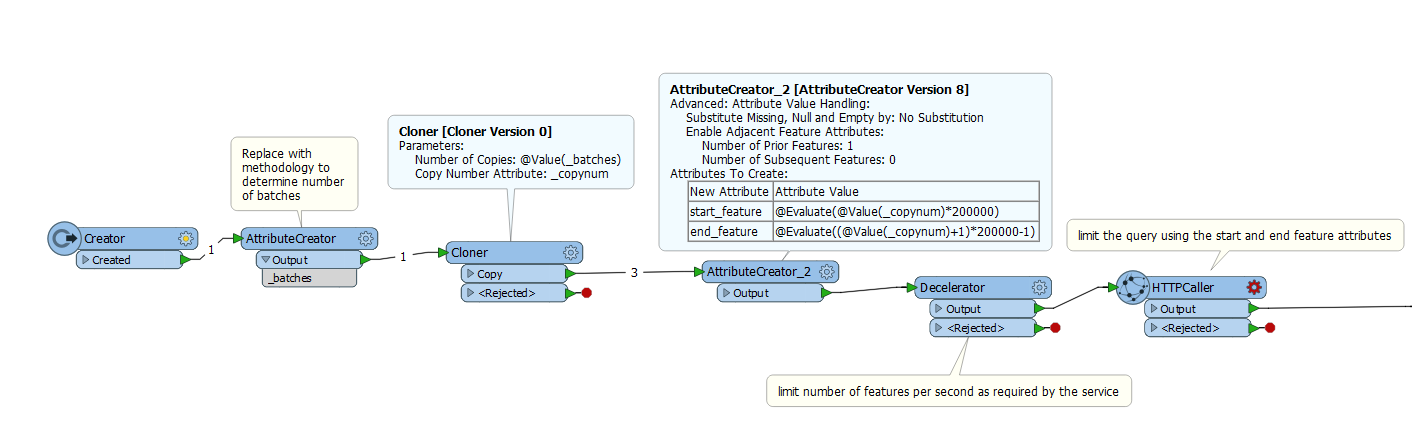
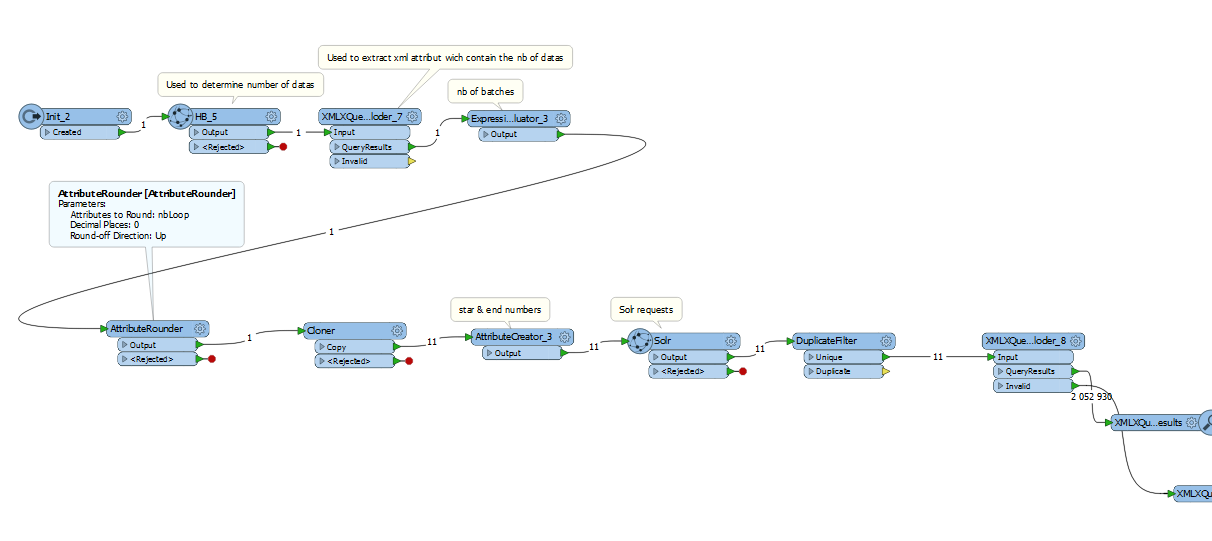
I'm requesting a Solr index to fetch some datas, and I'm using an HTTPCaller to do that.
There's more than 10M documents indexed and I can't fetch them with just one Solr request.
So I would like to first, fetch 200 000 datas, from 0 to 200 000, and then fetch 200k more datas, from 200k to 400k etc etc... (I hope I'm clear).
I'm able to pass attributes directly on the Solr url used to fetch those datas. I've also find a way to know dynamicly how many times, I'll have to loop. But I don't know how to loop, on the caller, and change the variables on it to increment the number and the range of the datas I need to fetch.
So do you know any way, to loop and fetch the datas 200k per 200k ?
Thanks by advance,
Kind regards,
Nicolas