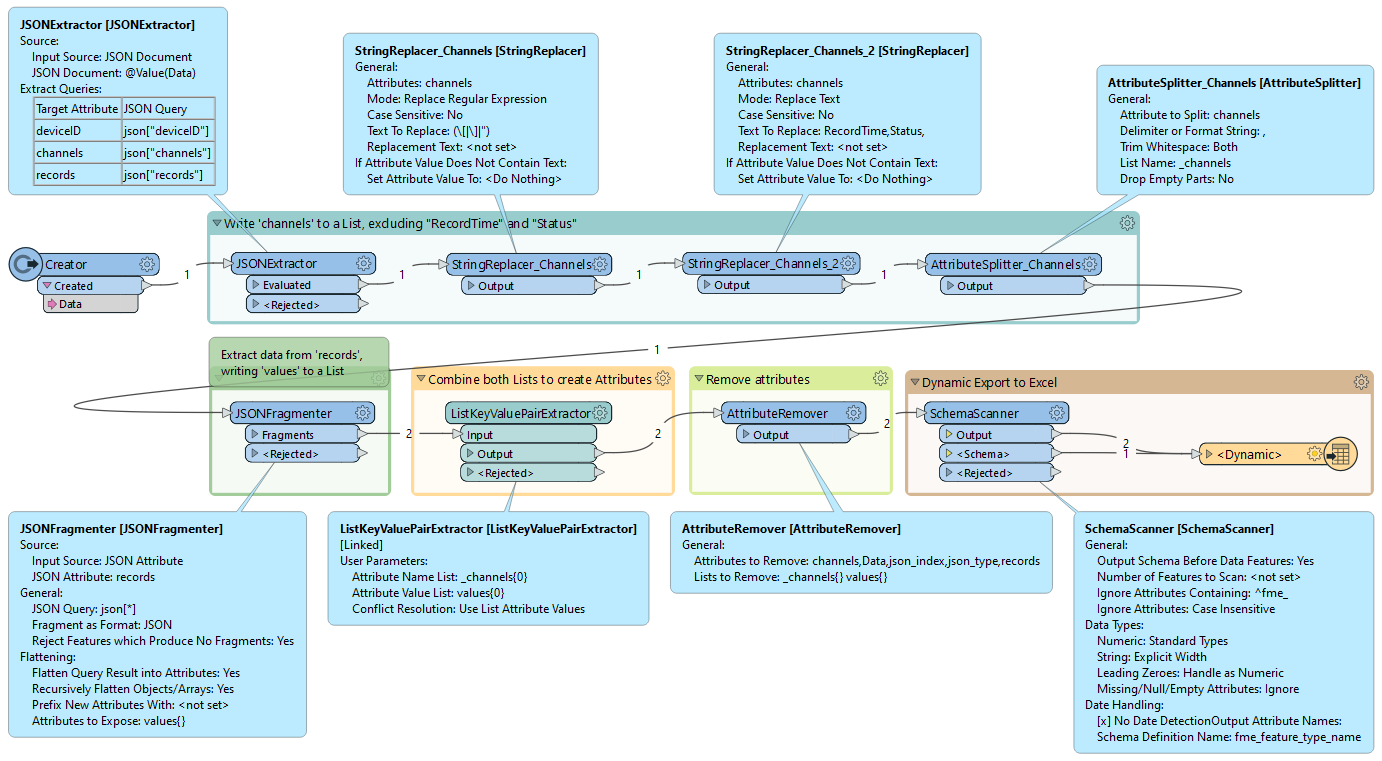
Hello,
I have the following JSON file (sample) where by te attributes names are under “Channels” while the data values are under records. This JSON come to me as a API call and have no way of modifying the source.
Using FME 2019
{
"deviceID": 12345,
"channels": [
"RecordTime",
"Status",
"Current Total Average Main",
"Current Total Average Load1",
"Voltage Total Average Total",
"PhaseAngle Total Average Main",
"PhaseAngle Total Average Load1",
"Voltage Total Instantaneous Total",
"Current Total Instantaneous Main",
"Current Total Instantaneous Load1",
"PhaseAngle Total Instantaneous Main",
"PhaseAngle Total Instantaneous Load1",
"ModemSignalStrength Total Average Total"
],
"records": [
{
"recordingTime": "2002-03-03T00:00:00",
"status": "None",
"values": [
2.781,
0,
237.95,
37.4,
0,
238.27,
2.804,
0,
37.66,
0,
14.82
]
},
{
"recordingTime": "2002-03-03T00:05:00",
"status": "None",
"values": [
2.351,
0,
238.14,
42.7,
0,
238.19,
2.267,
0,
44.55,
0,
15
]
}
]
}
Ideally i would like to have the output as a table format. The data also changes with different channels both in names and counts depending on the IoT device. Any hints would be greatly apricated.
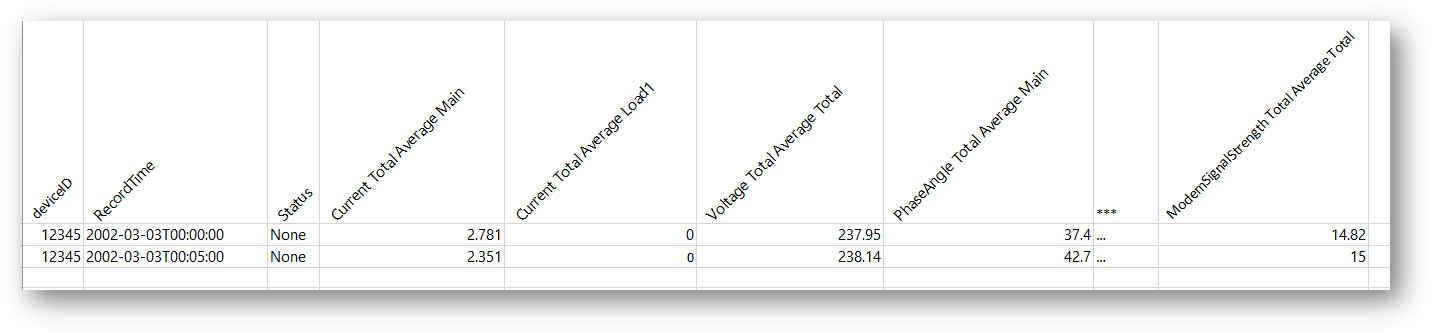
I am down the track with python at the moment
data = json.loads(feature.getAttribute('json'))
channels = data['channels']
records = []
deviceID = data['deviceID']
for record in data['records']:
row = {channels[i+2]: record['values'][i] for i in range(len(record['values']))}
row['RecordTime'] = record['recordingTime']
row['Status'] = record['status']
row['DeviceID'] = deviceID
f = fmeobjects.FMEFeature()
for K, V in row.items():
f.setAttribute(K, V)
self.pyoutput(f)
#self.pyoutput(feature)