Hi there...
I a list containing adress inforation. The lenght of the list varies from featur to feature so I need a flexible solution... The list looks like this:
_list{0}.name = "Company 1"
_list{0}.zip = "ZIP-Code 1"
_list{0}.city = "City 1"
_list{1}.name = "Company 2"
_list{1}.zip = "ZIP-Code 2"
_list{1}.city = "City 2"
_list{2}.name = "Company 3"
_list{2}.zip = "ZIP-Code 3"
_list{2}.city = "City 3"
:
_list{n}.name = "Company n"
_list{n}.zip = "ZIP-Code n"
_list{n}.city = "City n"
As you see...the list is of dynamic length... The task is now, to write some of the list elements into attributes:
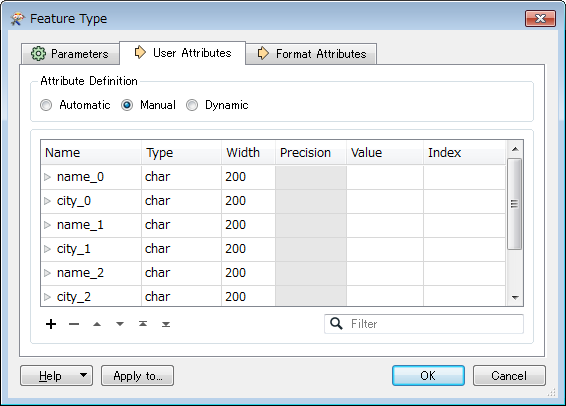
_list{0}.name => name1
_list{0}.city => city1
_list{1}.name => name2
_list{1}.city => city2
_list{2}.name => name3
_list{2}.city => city3
:
_list{n}.name => name_n
_list{n}.city => city_n
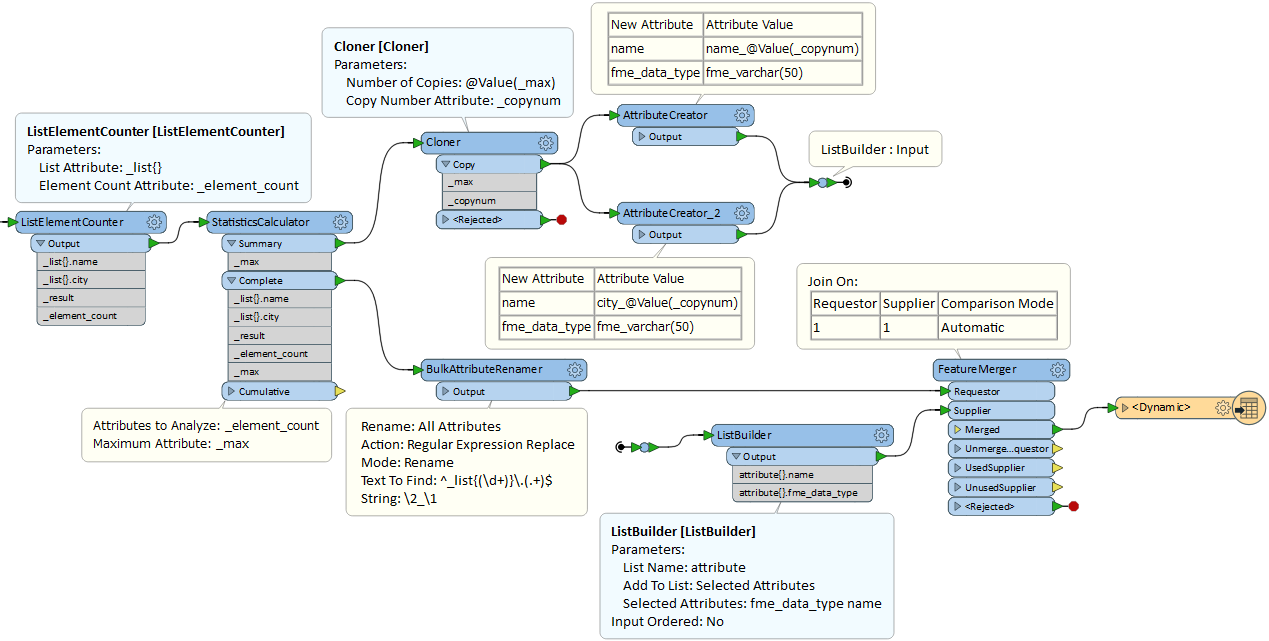
So I need to create a dynamic number of attributes. I tried the attribute manager, list renamer, list exploder - but not really satisfying. The only way so far is to use the attribute creator but I have no idea how to implement a dynamic number of attributes...
Does anyone has an idea?????
Thanks in advance