

I need to read from a file with multiple records only the columns name that start with a prefix and convert them into a list to do some processing after with those column names. This is what I've got so far
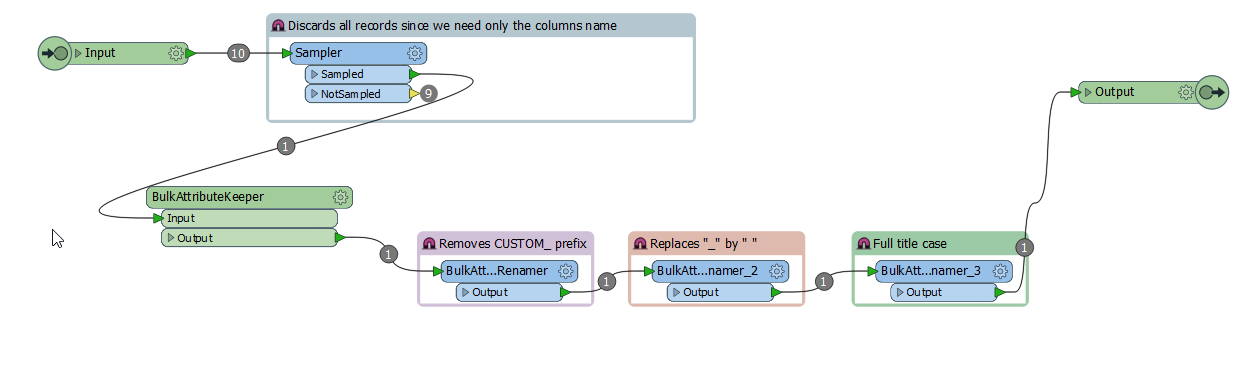
This is the output with the column names that I need. But I need to convert those into a list to do some processing for every column name. How could I achieve that?

Thanks






