



Hi list.
I'm tasked with importing a lot of feature sets, each with its own set of fields/attributes. So I'm using dynamic output mode, utilizing the schema features read.
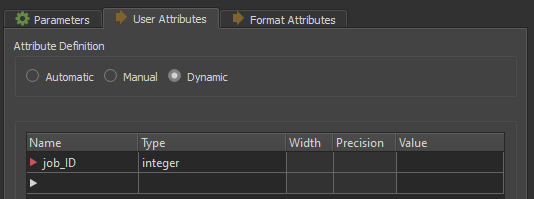
Unfortunately the request is to add a "job ID", so I tried to append an entry to the attribute list of the schema features, but suddenly the proces fails, not recognizing the schema features anymore. And this without changing anything in the data features flow nor the writer.
An example of the error message is:
Microsoft SQL Server Spatial Writer: A feature has arrived with 'fme_feature_type' of DAF_DAGI.afstemningsomraade_908308, but the feature type is not recognized. Halting translationMy writer setup is shown in the attached image. Why does the writer suddenly confuse the fme_feature_type with the requested table name ?
Or is the error message false/misleading ?
The "fme_feature_type" of the data features are the exact same, I just manipulated the schema features in a parallel "stream".
Any insights are appreciated.
Cheers.








")
