



Hi folks!
I am torn as to what workflow to use between FME and python. I am more comfortable with FME so hopefully FME would be the winner here.
The workflow I am trying to achieve for the business user is to have a GIS editable feature layer containing field summaries translate into a docx with a table template (ideally with the same attributes as the GIS feature layer).
A sample of the table template in the docx is below:
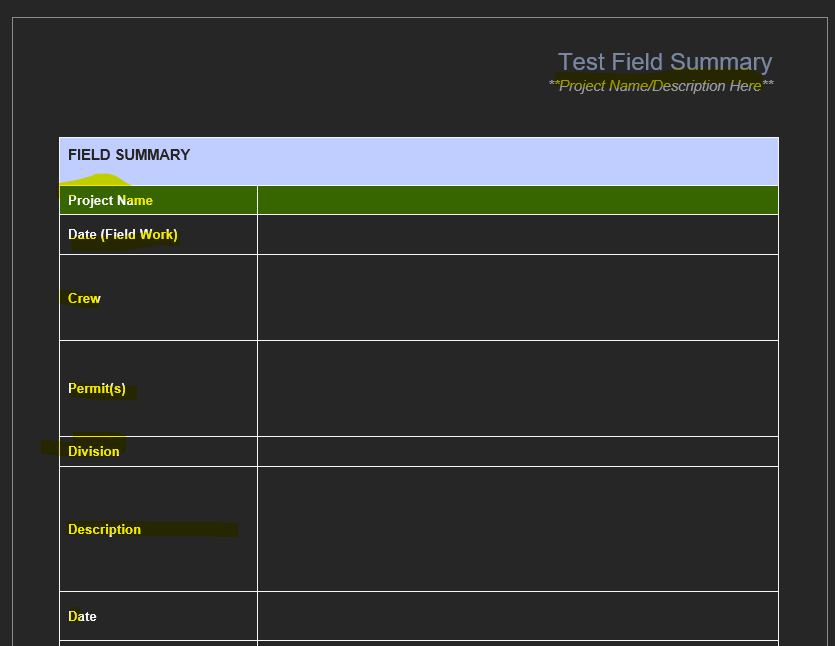
Any time a new field summary project gets entered into the GIS editable feature layer, ideally, a net new Word document with a separate table with populated values from the GIS editable feature layer will populate in the corresponding values in the table within the docx. Any updates that are made to existing field work project records within the GIS editable feature layer would have the updated records/values also translate into the associated Word Document with table template values as well.
So in the above, the values from the project name, date, crew, permits, division, description and date from the GIS feature class would get pushed into the relevant table values of the same named fields in the template docx (and generate a net new docx for each new field summary project, or find the existing docx and have the relevant table values be updated when any of the corresponding records in GIS gets updated).
Would this be a somewhat common workflow that one would be able to accomplish with FME and GIS or would you think this would be more suited to Python?
I am working to add in placeholders in the appropriate blank column (i.e. <<Project_Name», <<Crew», <<Date», etc) but am having trouble finding a Word based Transformer that would replace these placeholders with the appropriate field values from the GIS FC. When I am experimenting with the MSWordStyler, it seems to populate a new table but in the format as the screenshot above with each horizontal row being populated in the table.
Thanks in advance!










