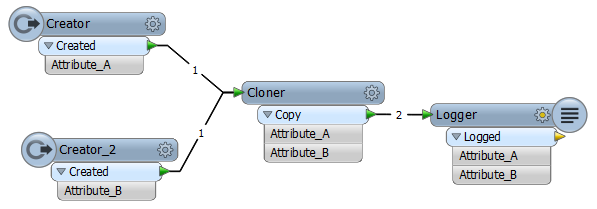
I was wondering i this is intendend.
On a reader i choose to not expose certain attributes, say SetA
I thought this would exclude them from further operations.
I do a comparison with another set, SetB. This set has an attribute wich should be, on passing certain conditions, passed to SetA. This attribute is one of the none-exposed in SetA., as SetA is not allowed to dictate its value.
Now i found that not exposing the attribute on set A does not exclude it from the operation, it fouls up the result. Even after not exposing it, i still need to remove the attribute.
Seems somewhat uselss to me, that option to expose or not on the reader, or not ?
Gio