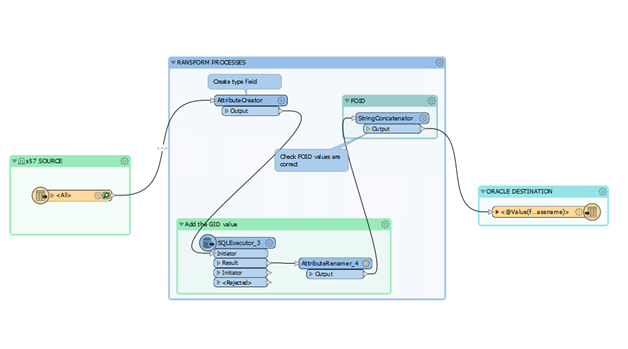
I want to run a batch process to load a series of file-based datasets in a folder, do some simple transformations and export each to a database table. The workspace in the image below is run by a workspace runner. The complication is that each source has some standard columns and an unknown quantity of additional columns, which need to be loaded into the database as a new table. If I configure the workspace with one source file, the schema config will not be correct for another file. How can I set the schema definition to be dynamic? I’ve been researching the subject but have not found the answer.