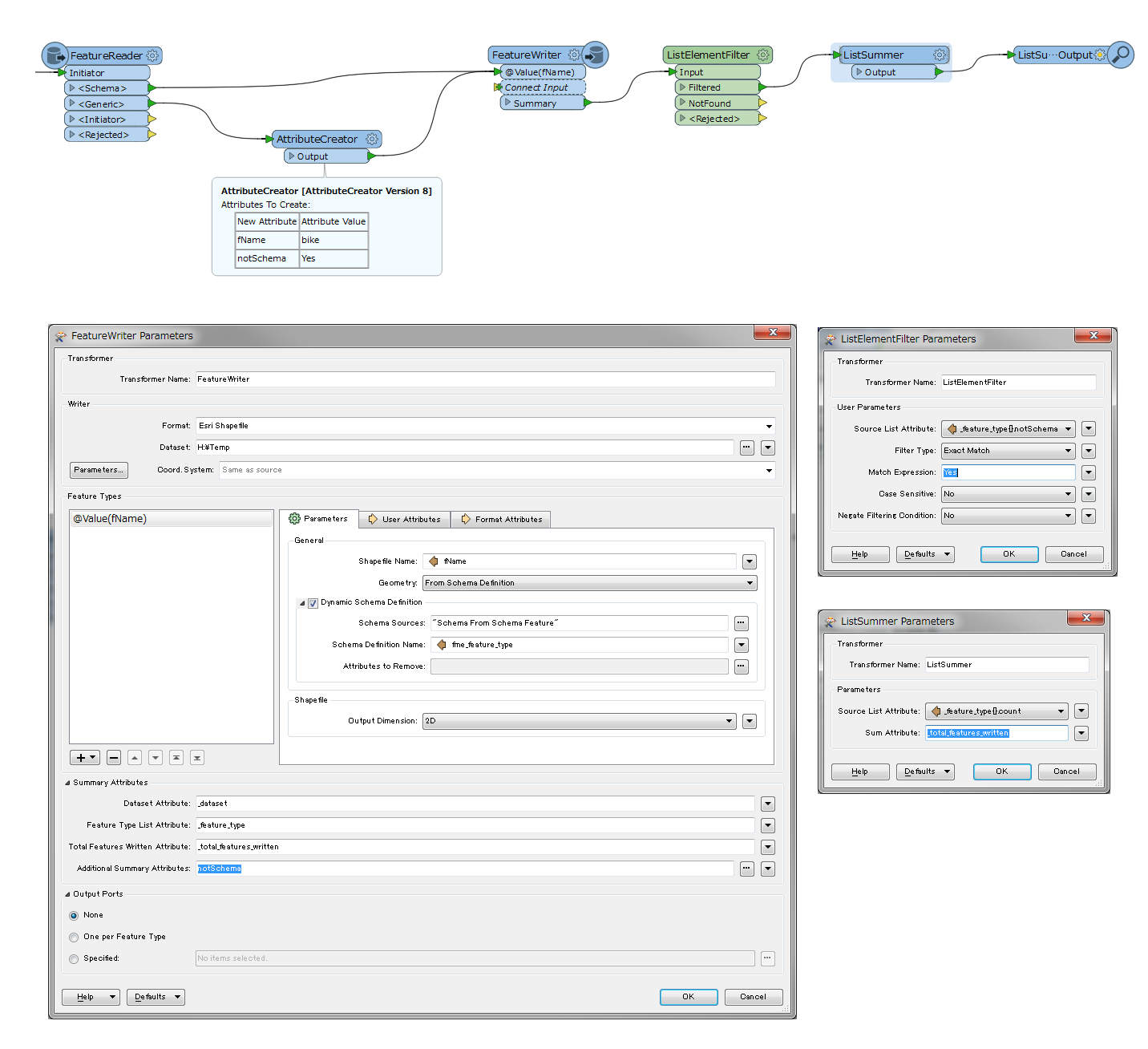
I have a scenario where I need to dynamically read in some data (FeatureReader), do a bit of filtering and write it out dynamically with the FeatureWriter and then continue processing.
Since there's no reader to point to in the Dynamic Schema Definition Schema Sources, I'm using "Schema From Schema Feature". This creates the correct output file with the correct number of features.
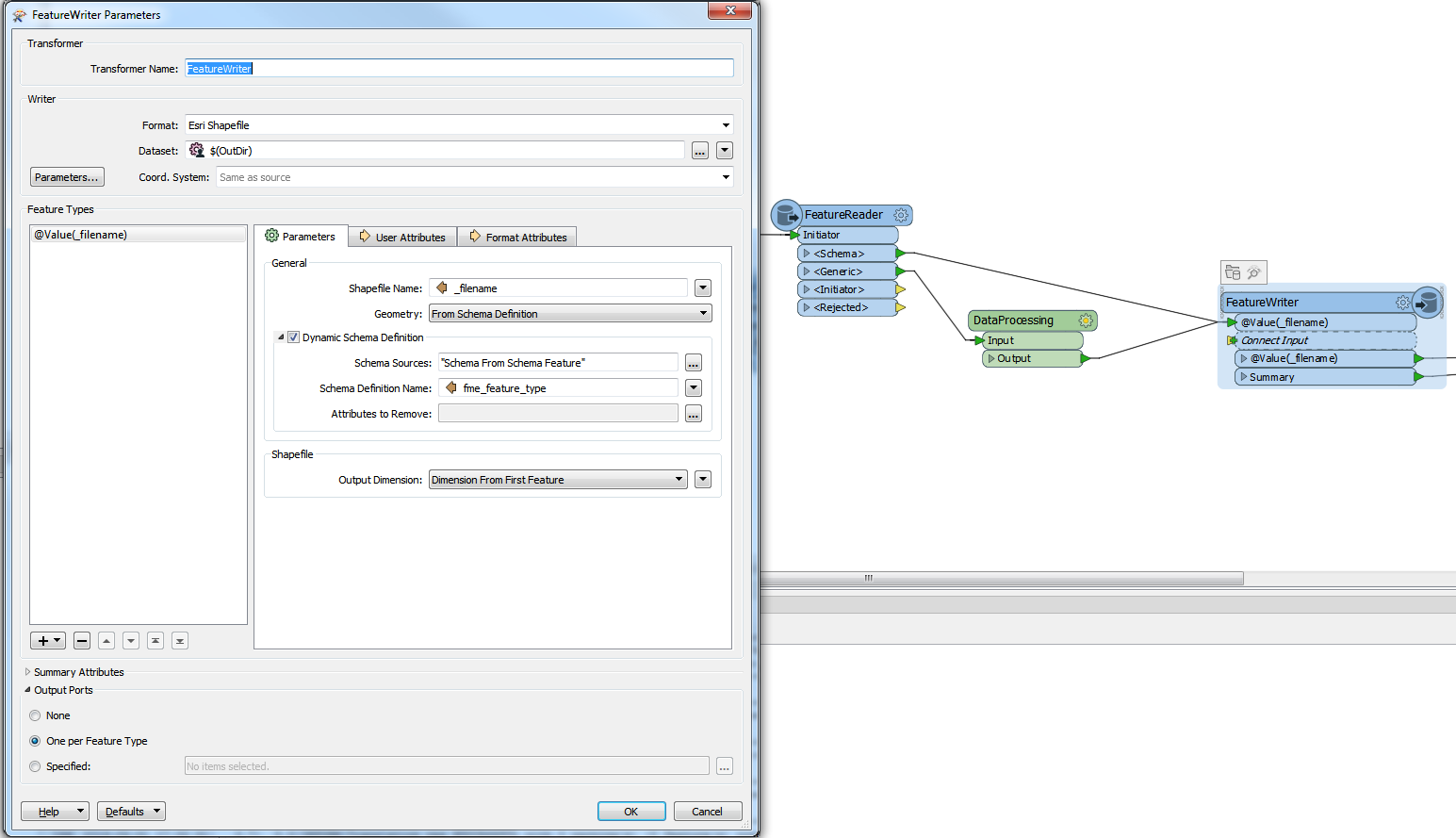
However, the Summary port feature is including the schema feature in the _total_features_written attribute, so is one more than the number of features recorded in the log, and also outputs it through the Feature Output Port.
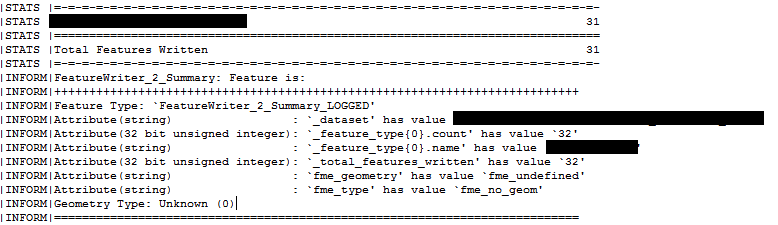
Is this the desired behaviour?