

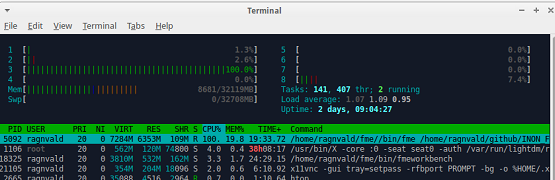
I have tried setting the dissolvers parallel processing level to extreme, but the job has no signifcant speed increase.
I am using Edition: FME Desktop Microsoft SQL Server Edition (floating) Version: FME(R) 2015.1.2.0 (20150911 - Build 15538 - linux-x64)