")

I'm trying to get to the bottom of this non-spatial data issue and am racking my brain to no avail...
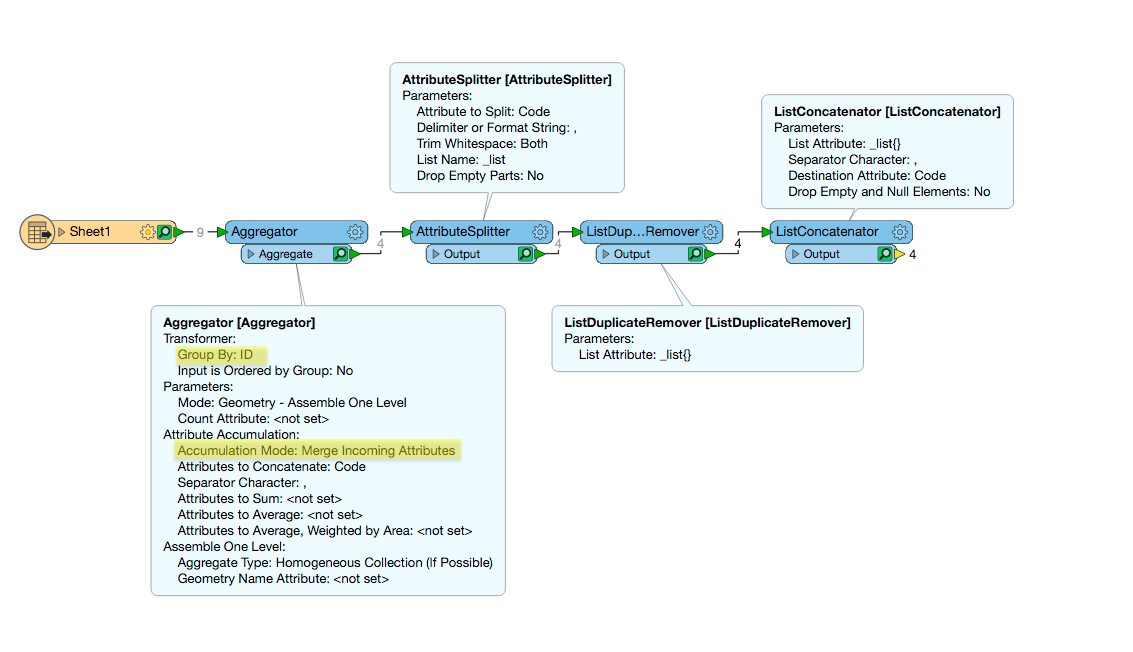
I have a table of data that looks as follows...
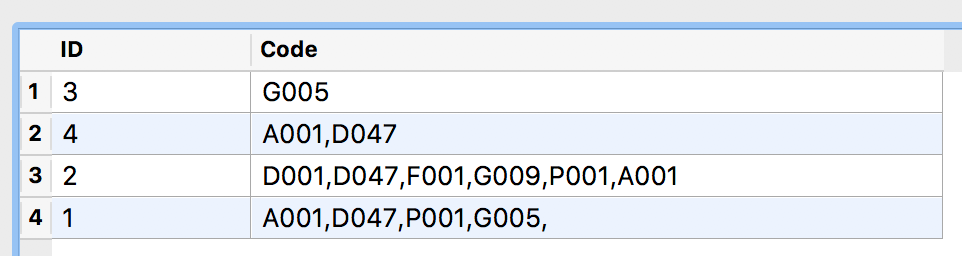
IDFacilityCode1A001,D0471D047,P001,G00512D001,D047,F0012F001,G0092P001,A0013G0053G0054A001Notice that the FacilityCode may be duplicated between records for any particular ID. I need my final table to just be a DISTINCT list of IDs with an alphabetized list of unique FacilityCodes, so it should look like this...
IDFacilityCode1A001,D047,P001,G0052A001,D001,D047,F001,G009,P0013G0054A001Theoretically, I'm thinking I might be able to use regex to extrapolate the unique FacilityCodes including the comma-separated values for the records with multiple FacilityCodes (with a StringSearcher? Not even sure what my regex would look like), then a ListDuplicateRemover, a ListSorter (to alphabetize), then a ListConcatenator to bring my list back to a single attribute.
I'm not even certain that could all work correctly while maintaining a grouping on the ID. I thought about using a SELECT GROUP_CONCAT(FacilityCode,",")) sql statement with an inlinequerier, then going from there...but I'm not certain how well that would work either.
Thanks in advance for any help! I'll keep this post updated if I find any solutions on my own. I'm running a 2015 version of FME via ArcGIS 10.3 data interop.