
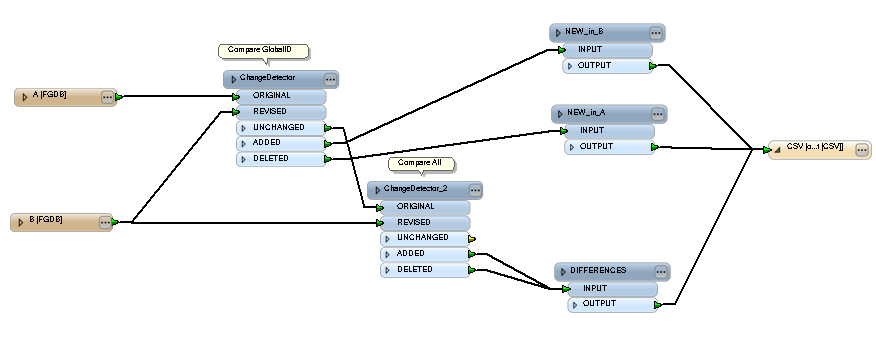
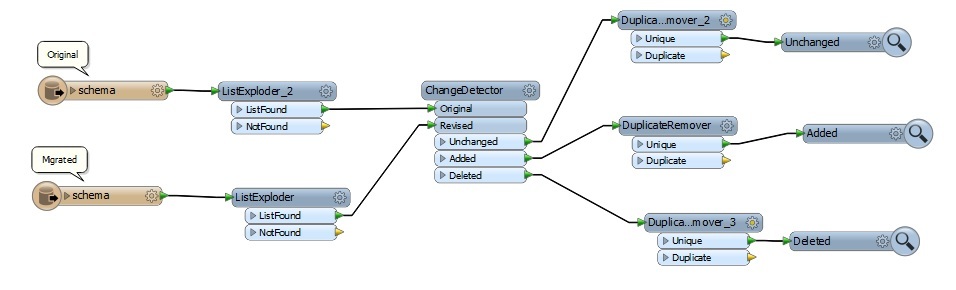
Hello I just started learning FME. What I need to do is to find any difference in attributes between two versions of the same feature class. In details, I have a copy of a FGDB feature from one vendor and another copy from another vendor. I want to create FME workspace to be able to find any difference between these two versions and write the difference to a csv file. Both versions have the same schema and I am only interested in the attribute difference at this point. The feature class has a GlobalID which is unique in both versions. The output csv should be able to give info like new records from version 1, new records from version 2, attribute difference for Field 1 for record {aud1123ksfs34400}, and so on. Currently I have a python script for this purpose, but my new manager wants to use a FME job to automate this. What type of reader, transformer and writer I should use to achieve this purpose? Please help!

Question
compare two versions of a feature class to find difference
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.



")
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.